require('readr')
df <- suppressMessages(read_csv("https://drive.google.com/uc?export=download&id=1OStFMmg5fzIpfTZnzX9Ql8sefN7se5SW", col_names=TRUE)) #df.csv, archivo con su ruta en el disco
df2 Sesión R2
Keywords
R, SPSS, TMIM, UV, Marketing, Multivariante
2.1 Ejercicio: Creación de un script rmarkdown
Para iniciar esta segunda sesión, vamos a hacer un nuevo experimento. Anteriormente, trabajamos con archivos de scripting normal y ahora vamos a hacerlo con el llamado scripting markdown que es el que nos permitirá crear informes reproducibles.
El ejercicio consistirá en utilizar las opciones de ejemplo para que el estudiante vea la diferencia entre trabajar con archivo .R y archivos .Rmd,con la particularidad de su salida a HTML, Diapositivas (ioslides) o PDF si se dispone de la utilidad adecuada instalada.
- File > New > New RMarkdown > Documentation > HTML
- File > New > New RMarkdown > Presentation > ioslides
Practicando con Rmarkdown …
2.1.1 Ejercicio: script 05
Por último, practiquemos la carga de datos. Aunque RStudio proporciona herramientas en su IDE para poder cargar datos desde archivos de texto, Excel © o SPSS © preferimos que la carga del archivo se haga desde el mismo script de trabajo. Por ello, usaremos los paquetes readr para ficheros de texto, readxl para archivos xls o xlsx y expss para archivos SPSS. Las instrucciones serán muy simples. Para evitar repetir la carga en las diferentes secciones de este capítulo, cargamos inicialmente todos los archivos. Los paquetes mencionados deberán haber sido cargados previamente.
2.1.1.1 Carga desde CSV
El script que permitiría la lectura de un archivo denominado ‘df.csv’ (texto separado por comas)…
2.1.1.2 Carga desde SPSS
El script que permitiría la lectura de un archivo denominado ‘3192.sav’ (archivo SPSS © etiquetado)…
require('expss')# se necesita el paquete expss; si no está cargado, cárgalo
data <- suppressMessages(read_spss("https://drive.google.com/uc?export=download&id=11q4pg2iWwWdV9mk5P44ejoAcj5CJEfJM")) # 3192.sav, archivo con su ruta en el disco
head(data, 5)tail(data, 5)Nuestros dataframe df y data están cargados y listos para ser utilizados a lo largo de las sesiones.
2.1.2 Ejercicio: script 05
Obtención de una tabla de frecuencias estilo SPSS.
Nótese que la tabla sale igual con las dos formas, pero mientras que en el primer caso se usa la nomenclatura estándar de R, y el campo se llama data$P31, es decir nombre del marco de datos en R (data) el símbolo del $ que separa y nombre del campo en el marco de datos P31 en la segunda al definir de inicio que se utilizará dataya se usa el nombre P31directamente, aunque debamos dar la orden de cálculo con el comando calculate().
fre(data$P31)| Sexo de la persona entrevistada | Count | Valid percent | Percent | Responses, % | Cumulative responses, % |
|---|---|---|---|---|---|
| Hombre | 1256 | 49.1 | 49.1 | 49.1 | 49.1 |
| Mujer | 1301 | 50.9 | 50.9 | 50.9 | 100.0 |
| #Total | 2557 | 100 | 100 | 100 | |
| <NA> | 0 | 0.0 |
2.1.3 Ejercicio: script 06
Para este script, indicaremos que usamos la fuente de datos cargado anteriormente. Redactamos pues nuestro script, donde identificamos el dataframe, el campo P31 del cual vamos a calcular el número de casos.
# Script 6data %>%
tab_cells(P31) %>%
tab_stat_cases() %>%
tab_pivot()| #Total | |
|---|---|
| Sexo de la persona entrevistada | |
| Hombre | 1256 |
| Mujer | 1301 |
| #Total cases | 2557 |
2.1.4 Ejercicio: script 07a
Realicemos ahora una pequeña pero importante variación en el cálculo del estadístico casos -frecuencias- y utilicemos la posibilidad de ubicar donde queramos el total de casos, así como su etiqueta. Ello lo hacemos con total_row_position = "above", label = "Casos" aplicado a la función tab_stat_cases().
data %>%
tab_cells(P31) %>%
tab_stat_cases(total_row_position = "above",
label = "Casos") %>%
tab_pivot()| #Total | ||
|---|---|---|
| Sexo de la persona entrevistada | ||
| #Total cases | Casos | 2557 |
| Hombre | Casos | 1256 |
| Mujer | Casos | 1301 |
2.1.5 Ejercicio: script 07b
Si en lugar de obtener casos (valores absolutos) queremos sacar valores porcentuales, el cambio es mínimo. Usaremos el comando tab_stat_cpct() para indicarlo.
# Script 7b
data %>%
tab_cells(P31) %>%
tab_stat_cpct(total_row_position = "above",
label = "% casos") %>%
tab_pivot()| #Total | ||
|---|---|---|
| Sexo de la persona entrevistada | ||
| #Total cases | % casos | 2557 |
| Hombre | % casos | 49.1 |
| Mujer | % casos | 50.9 |
2.1.6 Ejercicio: script 08
Cuando deseamos hacer combinaciones de frecuencias y porcentajes, la filosofía de trabajo es muy parecida. En nuestro caso vamos a hacer algo muy típico. Aunque creo que resulta más sencillo leer cada estadístico en su tabla, hay ocasiones en las que la comparativa es muy necesaria y por tanto es necesario unir los estadísticos en la misma tabla. Nótese la diferencia con el siguiente cuadro…
# Script 8
data %>%
tab_cells(P31) %>%
tab_stat_cases(total_row_position = "above",
label = "Casos") %>%
tab_stat_cpct(label = "% casos") %>%
tab_pivot(stat_position = "inside_columns")| #Total | ||
|---|---|---|
| Casos | % casos | |
| Sexo de la persona entrevistada | ||
| #Total cases | 2557 | 2557 |
| Hombre | 1256 | 49.1 |
| Mujer | 1301 | 50.9 |
2.1.7 Ejercicio: script 09
Diferentes modalidades de cálculo de los porcentajes.
# Script 9
data %>%
tab_cells(P31) %>%
tab_stat_cases() %>%
tab_stat_cpct() %>%
tab_stat_rpct() %>%
tab_stat_tpct() %>%
tab_pivot()| #Total | |
|---|---|
| Sexo de la persona entrevistada | |
| Hombre | 1256.0 |
| Mujer | 1301.0 |
| #Total cases | 2557 |
| Hombre | 49.1 |
| Mujer | 50.9 |
| #Total cases | 2557 |
| Hombre | 100.0 |
| Mujer | 100.0 |
| #Total cases | 2557 |
| Hombre | 49.1 |
| Mujer | 50.9 |
| #Total cases | 2557 |
2.1.8 Ejercicio: script 10
Efecto de los modificadores.
# Script 10
data %>%
tab_cells(P31) %>%
tab_stat_cases(total_row_position = "below",
label = "N") %>%
tab_stat_cpct(label = "V% casos") %>%
tab_stat_rpct(label = "H% casos") %>%
tab_stat_tpct(label = "T% casos") %>%
tab_pivot(stat_position = "inside_columns")| #Total | ||||
|---|---|---|---|---|
| N | V% casos | H% casos | T% casos | |
| Sexo de la persona entrevistada | ||||
| Hombre | 1256 | 49.1 | 100 | 49.1 |
| Mujer | 1301 | 50.9 | 100 | 50.9 |
| #Total cases | 2557 | 2557 | 2557 | 2557 |
2.1.9 Ejercicio: script 11
La función var_lab() nos permite manipular la etiqueta de una variable, un texto descriptivo de su significado.
Prueba en tu consola a escribir ?expss::var_lab()
# Script 11
var_lab(data$P31)[1] "Sexo de la persona entrevistada"var_lab(data$P31) <- 'Género del entrevistado'
var_lab(data$P31)[1] "Género del entrevistado"2.1.10 Ejercicio: script 12
La función val_lab() nos permite manipular las etiquetas de una variable, definir las etiquetas de los códigos, factores o niveles.
Prueba en tu consola a escribir ?expss::val_lab()
# Script 12
val_lab(data$P31)Hombre Mujer
1 2 val_lab(data$P31) <-
c('masculino'=1,
'femenino'=2)
val_lab(data$P31)masculino femenino
1 2 2.2 A fondo con el proceso de datos con tablas y cuadros
En esta documentación acerca de R, mostramos un conjunto de términos que serán habitualmente utilizados en los sucesivos capítulos que se presentan en este documento. estos son los más relevantes y los hemos separado en dos grupos. un grupo hace referencia a términos básicos de R y otro grupo a términos básicos del manejo de tablas o del proceso de tabulación. Cada término tiene une breve reseña, y posteriormente algunos de ellos serán más tratados en sus respectivas funcionalidades.
2.2.1 Términos básicos de proceso de datos
- variable, elemento de tipo vector que contiene los valores de una determinada observación, un valor en cada fila; debe entenderse en el contexto de la estructura tabular o dataframe.
- valores, cada una de las diferentes celdas que componen un dataframe. Una variable toma un valor en cada fila y se representa en la celda.
- medidas, valores de los que se pretende calcular estadísticos como la media, la desviación típica o la mediana entre otras. Suelen responder a escalas de tipo numérico (ordinal o métrico).
- dimensiones, valores de los que se pretende calcular frecuencias y/o porcentajes.
- factores, niveles, códigos, etiquetas de variable.
- NA, es como R representa los valores nulos o ausentes.
- valores perdidos, missing values, valores ausentes; tal como hemos indicado en el término NA, así es como R representa este tipo de valores.
2.2.2 Términos básicos de tabulación
En nuestro trabajo vamos a crear objetos de tipo tabla; una tabla es una estructura tabular, igual que un dataframe. De hecho, con nuestro trabajo utilizando el paquete EXPSS, vamos a generar tablas que serán dataframe de tipo (clase) etable. Al ser un dataframe, podremos operar entre filas, columnas y celdas de forma lógica o aritmética utilizando funciones y comandos de R.
Dejamos este glosario de términos relacionados con las tablas que utilizaremos en esta guía.
- título (caption), texto que se publicará sobre la tabla;
- pie (footer), texto que se publicará bajo la tabla;
- fila, cada una de las líneas de información dentro de una tabla; se suele asimilar a un nivel (código) de una variable y/o a un resultados estadístico de una variable;
- columna, cada una de las variables que conforman el dataframe de una tabla (estructura tabular); en un cuadro o tabla de contingencia suele equivaler a un nivel de la variable que originalmente se diseñó para ser usada en columnas (si por ejemplo SEXO, una columna sería hombre y otra mujer);
- celda, cada una de las unidades de información del cuadro o tabla;
- row_labels, primera columna donde se escriben los textos de las filas y que sirven para identificar el contenido de las mismas;
- etiqueta de variable, texto extra identificativo de la variable usada en filas o columnas;
- etiqueta de valor, texto del código identificativo de la variable usada;
- estadístico, medida calculada;
- frecuencia, tipo específico de medida calculada que significa número de veces en términos absolutos;
- porcentaje, tipo específico de medida calculada que significa número de veces en términos relativos;
|, símbolo denominadopipeque en el paqueteexpssse utilizará para separar conjuntos de texto en una celda (o columna o fila);- significación, prueba estadística de contraste.
2.3 Carga de datos para la sesión
Procedamos a ejecutar el siguiente script para cargar los paquetes necesarios y los datos del estudio CIS 3192, barómetro sanitario de 2017.
suppressMessages(library('highcharter', quietly=TRUE))
suppressMessages(library('expss', quietly = TRUE))
options(highcharter.theme = hc_theme_hcrt(tooltip = list(valueDecimals = 2)))
data <- suppressMessages(read_spss("https://drive.google.com/uc?export=download&id=11q4pg2iWwWdV9mk5P44ejoAcj5CJEfJM"))
head(data, 5) ESTU CUES CCAA PROV MUN TAMUNI CAPITAL DISTR SECCION ENTREV OLA P1 P2 P3 P401
1 3192 1 16 1 59 5 1 0 0 0 3 9 3 6 1
2 3192 2 16 1 59 5 1 0 0 0 3 2 2 7 1
3 3192 3 16 1 59 5 1 0 0 0 3 2 2 8 1
4 3192 4 16 1 59 5 1 0 0 0 3 9 2 8 1
5 3192 5 16 1 59 5 1 0 0 0 3 3 2 7 1
P402 P403 P404 P501 P502 P503 P504 P6 P6A01 P6A02 P6B P6C P6D P7 P7A P801
1 1 1 1 7 7 8 8 1 2 0 1 2 3 3 1 1
2 1 1 1 7 7 7 7 1 1 0 0 2 3 1 NA 1
3 1 1 1 8 8 8 8 1 2 0 2 2 2 3 1 1
4 1 1 1 9 9 9 1 1 1 0 0 1 3 2 NA 1
5 1 1 1 9 5 8 8 1 2 0 1 2 3 4 1 1
P802 P803 P8A01 P8A02 P8A03 P8B01 P8B02 P8B03 P901 P902 P903 P904 P905 P906
1 2 1 2 0 1 96 96 8 7 7 7 7 6 6
2 1 1 2 2 1 96 96 7 7 7 7 7 7 7
3 1 1 1 2 1 10 96 10 8 8 8 8 6 8
4 2 1 1 0 2 9 96 96 10 98 10 98 5 7
5 1 1 2 2 2 96 96 96 8 8 9 9 6 8
P907 P908 P1001 P1002 P1003 P11 P11A01 P11A02 P11B P11C P11D P12 P12A01
1 6 7 3 2 3 2 96 96 0 0 0 2 96
2 7 1 3 2 3 2 96 96 0 0 0 1 2
3 8 2 2 3 3 2 96 96 0 0 0 1 1
4 7 3 2 3 2 2 96 96 0 0 0 1 1
5 8 4 2 3 2 2 96 96 0 0 0 1 1
P12A02 P12B P12C P12D01 P12D02 P12D P1301 P1302 P1303 P1304 P1305 P14 P14A01
1 96 0 0 NA NA NA 6 7 7 6 3 2 96
2 0 2 3 97 97 9997 7 7 7 7 1 2 96
3 0 2 3 25 0 25 7 7 7 7 2 2 96
4 0 1 3 0 1 30 9 9 10 10 3 2 96
5 0 2 3 0 4 120 5 6 8 8 4 2 96
P14A02 P14B P14C P1501 P1502 P1503 P1504 P1505 P1506 P16 P17 P18 P18A P18B
1 96 0 0 7 7 5 5 6 2 3 2 1 8 1
2 96 0 0 7 7 9 7 7 1 4 8 2 0 0
3 96 0 0 7 7 7 7 7 2 2 3 2 0 0
4 96 0 0 8 10 4 8 9 3 2 8 1 10 2
5 96 0 0 5 10 7 5 98 4 8 2 1 10 2
P18C01 P18C02 P18C03 P18C04 P18C05 P18C06 P18C07 P18C08 P19 P20 P21 P21A01
1 NA NA NA 1 NA NA NA NA 2 2 2 0
2 0 0 0 0 0 0 0 0 2 2 2 0
3 0 0 0 0 0 0 0 0 2 2 2 0
4 0 0 0 0 0 0 0 0 3 2 2 0
5 0 0 0 0 0 0 0 0 2 2 2 0
P21A02 P21A03 P21A04 P21B P22 P23 P24 P2501 P2502 P2503 P2601 P2602 P2603
1 0 0 0 0 3 1 2 10 10 8 1 2 2
2 0 0 0 0 1 1 1 10 6 4 2 9 9
3 0 0 0 0 1 8 2 10 10 10 1 2 2
4 0 0 0 0 3 2 2 10 10 10 1 2 2
5 0 0 0 0 1 1 2 10 8 10 2 2 2
P2604 P27 P28 P29 P30 P30A P30AR P31 P32 P33 P34 P35 P35A P36 P37 P38 P39 P40
1 1 2 3 99 1 99 99 2 51 1 1 3 5 2 1 1 2 1
2 2 1 3 2 1 3 3 1 37 1 1 3 13 1 2 1 1 1
3 1 1 2 4 1 99 99 2 60 1 2 3 7 2 2 4 3 2
4 1 1 1 2 1 98 98 1 53 1 1 3 11 1 1 4 1 1
5 1 2 3 1 1 3 3 2 69 3 2 3 4 2 2 4 1 2
P41 P42 P42A P43 P44 P45 P46 P46A P46B P46C P46D P47 P47A P47B P48 P4901
1 561 2 1 87 99 99 1 1 0 0 0 1 16 0 1 NA
2 215 4 0 86 7 6 1 1 0 0 0 1 16 0 3 NA
3 351 1 3 35 10 7 1 1 0 0 0 1 16 0 1 NA
4 223 1 1 85 9 7 1 1 0 0 0 1 16 0 1 NA
5 921 1 3 81 5 5 1 1 0 0 0 1 14 0 1 NA
P4902 P4903 P4904 P5001 P5002 P5003 P5004 P5005 P5101 P5102 P5103 P5104 P5105
1 NA NA NA - - - - - - - - - -
2 NA NA NA - - - - - - - - - -
3 NA NA NA - - - - - - - - - -
4 NA NA NA - - - - - - - - - -
5 NA NA NA - - - - - - - - - -
P52 P53 P54 P55 I1 I2 I3 I4 I5 I6 I7 I8 I9 E101 E102 E103 E2 E3 E4 C1 C1A C2
1 2 2 2 2 7 NA 30 2 2 NA 12 NA 1 20 10 17 5 17 3 1 0 2
2 2 2 2 2 1 NA 11 NA 2 2 2 NA NA 20 10 17 5 17 1 1 0 1
3 2 2 1 1 2 NA 10 NA NA 1 NA NA NA 20 10 17 5 30 2 1 0 1
4 2 2 2 1 3 NA 31 NA 2 2 10 1 NA 20 10 17 5 18 2 1 0 1
5 2 2 2 2 4 NA 13 NA NA 1 9 NA NA 20 10 17 5 19 2 1 0 1
C2A C2B C3 C4 RECUERDO ESTUDIOS OCUMAR11 RAMA09 CONDICION11 ESTATUS PESO
1 1 0 1 0 99 5 5 4 7 2 0.925
2 0 0 1 0 3 6 2 4 1 1 0.925
3 0 0 1 0 99 5 3 2 8 2 0.925
4 0 0 1 0 98 6 2 4 2 1 0.925
5 0 0 1 0 3 3 9 4 8 5 0.925Para descargar el cuestionario (PDF), haz clic en este enlace. Para verlo puedes probar con este otro enlace.
2.4 Tablas marginales
Vamos a comenzar con un conjunto de tablas muy sencillas. En ellas representaremos los valores obtenidos del análisis de un campo extraído de nuestra fuente de datos de referencia, la tercera oleada del Barómetro Sanitario en España de 2017 del realizado y publicado por el CIS. Por ahora, trabajaremos sólo con la variable denominada P31 (sexo del entrevistado), variable medida en escala nominal, cuyas etiquetas (valores) son hombre (1) y mujer (2) y con la variable P3, escala de satisfacción (1-10) con el funcionamiento del sistema sanitario español, medida de 1 a 10. En nuestra fuente de datos tenemos 2557 casos (entrevistas realizadas).
Para ello utilizaremos un script, es decir una pocas líneas de código que mostraremos en este mismo documento con un fondo gris. Lo que quede fuera de ese trozo del documento, será como este texto que estoy escribiendo. Este texto que además, puede ser formateado como si de un HTML se tratará, es lo que llamamos un archivo markdown, y como es de R, pues lo llamamos rmarkdown. Verás que también este documento tiene títulos, que se obtienen anteponiendo el símbolo # desde 1 vez hasta 6 veces y que se corresponde con las etiquetas de título de HTML. Inicialmente, comentaremos las líneas del script utilizando el también el mismo símbolo, pero no al inicio de la línea sino al final Lo que quede por detrás de él, se considera un comentario.
2.4.1 Tablas de frecuencia
Este conjunto de tablas sólo trabajará que con el estadístico de cálculo de frecuencias. Comenzaremos con variables de respuesta simple, para luego avanzar a las variables de respuesta múltiple y al uso de medidas estadísticas básicas (suma, media, mediana, máximo, mínimo, etc..).
2.4.1.1 Variables de respuesta simple
2.4.1.1.1 Cálculo de frecuencias, estilo SPSS
Utilizaremos en estos ejemplos de forma inicial un campo del marco de datos, P31, de respuesta simple. La primera tabla que haremos responde a un recuento de frecuencias, y es muy usada para el análisis univariante de una campo. Este comando muestra una tabla básica utilizando la función fre() que copia la salida del SPSS. Nótese que la columna de porcentaje válido y porcentaje es igual ante la inexistencia de NA (valores perdidos).
fre(data$P31)| Sexo de la persona entrevistada | Count | Valid percent | Percent | Responses, % | Cumulative responses, % |
|---|---|---|---|---|---|
| Hombre | 1256 | 49.1 | 49.1 | 49.1 | 49.1 |
| Mujer | 1301 | 50.9 | 50.9 | 50.9 | 100.0 |
| #Total | 2557 | 100 | 100 | 100 | |
| <NA> | 0 | 0.0 |
Alternativamente se puede presentar la forma que trabajaremos a lo largo de este curso, esta forma es la denominada script encadenado, donde definimos el marco de datos al inicio, y encadenamos instrucciones con el símbolo %>% que irían línea a línea sucesivamente para una mejor lectura y comprensión del texto escrito; podrían perfectamente ir en una línea. Nótese que la tabla sale igual con las dos formas, pero mientras que en el primer caso se usa la nomenclatura estándar de R, y el campo se llama data$P31, es decir nombre del marco de datos en R (data) el símbolo del $ que separa y nombre del campo en el marco de datos P31 en la segunda al definir de inicio que se utilizará dataya se usa el nombre P31directamente, aunque debamos dar la orden de cálculo con el comando calculate().
data %>%
calculate(fre(P31))| Sexo de la persona entrevistada | Count | Valid percent | Percent | Responses, % | Cumulative responses, % |
|---|---|---|---|---|---|
| Hombre | 1256 | 49.1 | 49.1 | 49.1 | 49.1 |
| Mujer | 1301 | 50.9 | 50.9 | 50.9 | 100.0 |
| #Total | 2557 | 100 | 100 | 100 | |
| <NA> | 0 | 0.0 |
Veamos ahora cómo solicitaremos tablas de frecuencias, porcentajes y estadísticos simples con R.
2.4.1.1.2 Tablas de frecuencias (absolutos)
La segunda tabla que vamos a hacer, ya responde a la típica presentación de una tabla de contingencia, sólo que en este casos vamos a mostrar sólo un campo y por tanto no va a haber cruce de variables. En el paquete expss, para construir un cuadro deberemos indicar al menos:
- un marco de datos (dataframe en nomenclatura R)
- referenciar la variable sobre la que se deben calcular el estadístico seleccionado (frecuencia -casos-, media, mediana, máximo, mínimo…)
- una orden de impresión de tabla
Estos elementos básicos pueden completarse con campos de columnas, campos de filas, pruebas de significación, etc.. Iremos desarrollando estos conceptos a lo largo de este documento. ¡Vamos a por el cuadro!
La que ahora entregamos, es la estructura básica de un script de R con el paquete expss. A lo largo del documento veremos cómo ir introduciendo mínimas variaciones a esta estructura que te permitirán descubrir un sinnúmero de posibilidades que ofrece este paquete de R. Por ejemplo, podemos modificar la etiqueta de TOTAL o indicar donde debe situarse la fila que contiene el cálculo TOTAL. Todas estas posibilidades las puedes conocer en la documentación original del package, aunque en este manual trataremos de ir desgranado las más relevantes para nuestro objetivo. Inicialmente iremos añadiendo tras el operador %>% comentarios precedidos por el símbolo #. Estos comentarios irán desapareciendo a medida que avancemos en el manual, y sólo se recurrirá a ellos cuando se aporte alguna nueva funcionalidad.
El dataframe tendrá el nombre que le hayas indicado en la carga. Redactamos pues nuestro script, donde identificamos el dataframe, el campo P31 del cual vamos a calcular el número de casos:
data %>%
tab_cells(P31) %>%
tab_stat_cases() %>%
tab_pivot()| #Total | |
|---|---|
| Sexo de la persona entrevistada | |
| Hombre | 1256 |
| Mujer | 1301 |
| #Total cases | 2557 |
Realicemos ahora una pequeña pero importante variación en el cálculo del estadístico casos -frecuencias- y utilicemos la posibilidad de ubicar donde queramos el total de casos, así como su etiqueta. Ello lo hacemos con total_row_position = "above", label = "Casos" aplicado a la función tab_stat_cases().
data %>%
tab_cells(P31) %>%
tab_stat_cases(total_row_position = "above", label = "Casos") %>%
tab_pivot()| #Total | ||
|---|---|---|
| Sexo de la persona entrevistada | ||
| #Total cases | Casos | 2557 |
| Hombre | Casos | 1256 |
| Mujer | Casos | 1301 |
2.4.1.1.3 Tablas de frecuencias relativas
Si en lugar de obtener casos (valores absolutos) queremos sacar valores porcentuales, el cambio es mínimo. Usaremos el comando tab_stat_cpct()para indicarlo.
data %>%
tab_cells(P31) %>%
tab_stat_cpct(total_row_position = "above", label = "% casos") %>%
tab_pivot()| #Total | ||
|---|---|---|
| Sexo de la persona entrevistada | ||
| #Total cases | % casos | 2557 |
| Hombre | % casos | 49.1 |
| Mujer | % casos | 50.9 |
2.4.1.1.4 Tablas de absolutos y realativos (juntos)
Cuando deseamos hacer combinaciones de frecuencias y porcentajes, la filosofía de trabajo es muy parecida. En nuestro caso vamos a hacer algo muy típico. Aunque creo que resulta más sencillo leer cada estadístico en su tabla, hay ocasiones en las que la comparativa es muy necesaria y por tanto es necesario unir los estadísticos en la misma tabla. Nótese la diferencia con el siguiente cuadro…
data %>%
tab_cells(P31) %>%
tab_stat_cases(total_row_position = "above", label = "Casos") %>%
tab_stat_cpct(label = "% casos") %>%
tab_pivot(stat_position = "inside_columns")| #Total | ||
|---|---|---|
| Casos | % casos | |
| Sexo de la persona entrevistada | ||
| #Total cases | 2557 | 2557 |
| Hombre | 1256 | 49.1 |
| Mujer | 1301 | 50.9 |
Nótese el efecto introducido por el modificador de posición del cálculo. También …
data %>%
tab_cells(P31) %>%
tab_stat_cases(total_row_position = "above", label = "Casos") %>%
tab_stat_cpct(label = "% casos") %>%
tab_pivot(stat_position = "outside_rows")| #Total | ||
|---|---|---|
| Sexo de la persona entrevistada | ||
| #Total cases | Casos | 2557 |
| Hombre | Casos | 1256.0 |
| Mujer | Casos | 1301.0 |
| Hombre | % casos | 49.1 |
| Mujer | % casos | 50.9 |
| #Total cases | % casos | 2557 |
O también …
data %>%
tab_cells(P31) %>%
tab_stat_cases(total_row_position = "below", label = "Casos") %>%
tab_stat_cpct(label = "% casos") %>%
tab_pivot(stat_position = "inside_columns")| #Total | ||
|---|---|---|
| Casos | % casos | |
| Sexo de la persona entrevistada | ||
| Hombre | 1256 | 49.1 |
| Mujer | 1301 | 50.9 |
| #Total cases | 2557 | 2557 |
2.4.1.2 Variable de respuesta múltiple
Vamos a trabajar ahora con variables multi-respuesta. SPSS divide la variable múltiple en tantas variables simples (o dicotómicas binarias) como requiera para poder representar la multi-respuesta. Por ejemplo, si tenemos una variable múltiple denominada P01, y el máximo número de respuestas (menciones) en el banco de datos es 3, al crear el dataframe se crean las variables P01_1, P01_2 y P01_3; es con estas variables con las que trabajamos. Cada una de estas variables puede tomar cualquiera de los valores codificados.
Para expss, la forma de indicar que un conjunto de campos forman una multi-respuesta es muy simple anteponer mrset_f() al nombre del campo que vamos a usar. Debemos tener la precaución de que no haya variables en el banco de datos que comiencen por la misma raíz. Así, el campo de ejemplo sería mrset_f(P01_)y con eso procesaría las tres variables de forma conjunta. Alternativamente, podríamos usar también:
mrset(P01_1 %to% P01_3)o también,mrset(P01_1,P01_2,P01_3)
Cualquiera de ellas sería también válida, pero nótese que en estas últimas listadas, es necesario saber donde empieza y acaba la múltiple y esto puede variar sobretodo si creamos los scripts antes de acabar el campo. Al acabar el campo, pudiera haber algún nuevo caso que tuviera más menciones que 3 y por tanto existirían también _4, _5 o, _n.
Como hemos indicado, no olvides que existe otra forma de trabajar las múltiples, utilizando variables dicotómicas o binarias (así es como están en nuestro banco de datos del CIS). En este caso, serviría todo lo afirmado anteriormente, pero en lugar de mrset_f(), usaríamos mdset_f().
2.4.1.2.1 Tablas de frecuencias absolutas
Usaremos el campo P18C para procesar su información, que se localiza en el banco de datos desde P18C01 hasta P18C08.
data %>%
tab_cells(mdset_f(P18C)) %>%
tab_stat_cases(total_row_position="above", label="Casos") %>%
tab_pivot(stat_position="inside_columns")| #Total | |
|---|---|
| Casos | |
| #Total cases | 198 |
| La tarjeta sanitaria no funcionaba | 33 |
| El ordenador de la farmacia no funcionaba | 23 |
| Estaba fuera de plazo (era demasiado pronto o demasiado tarde) | 75 |
| No aparecían los medicamentos recetados | 57 |
| No pudo retirarlos en una comunidad autónoma distinta a la suya | 17 |
| Otro tipo de problema | 48 |
| No recuerda | |
| N.C. | 3 |
2.4.1.2.2 Tablas de frecuencias relativas
También se pueden, como es obvio, obtener porcentajes en las tablas marginales múltiples. A diferencia de cuando la variables es simple que todos los porcentajes suman 100, en las variables múltiples cada alternativa tiene un rango de 0 a 100, desde no ser elegida una opción en ningún registro del dataframe, hasta ser elegida por todos los registros. Usaremos nuevamente el campo P18C para procesar su información, que se localiza en el banco de datos desde P18C01 hasta P18C08.
data %>%
tab_cells(mdset_f(P18C)) %>%
tab_stat_cpct(total_row_position="above", label="% casos") %>%
tab_pivot(stat_position="inside_columns")| #Total | |
|---|---|
| % casos | |
| #Total cases | 198 |
| La tarjeta sanitaria no funcionaba | 16.7 |
| El ordenador de la farmacia no funcionaba | 11.6 |
| Estaba fuera de plazo (era demasiado pronto o demasiado tarde) | 37.9 |
| No aparecían los medicamentos recetados | 28.8 |
| No pudo retirarlos en una comunidad autónoma distinta a la suya | 8.6 |
| Otro tipo de problema | 24.2 |
| No recuerda | |
| N.C. | 1.5 |
Pero vamos a introducir una nueva variación. En una múltiple, también pueden calcularse los resultados en lo que se llama base respuestas, donde sí suman 100% los porcentajes nuevamente, pero recuerda que el porcentaje hace referencia a las respuestas, no a los individuos. En este caso el script modifica el estadístico solicitado.
data %>%
tab_cells(mdset_f(P18C)) %>%
tab_stat_cpct_responses(total_row_position="above", label="% casos") %>%
tab_pivot(stat_position="inside_columns")| #Total | |
|---|---|
| % casos | |
| #Total responses | 256 |
| La tarjeta sanitaria no funcionaba | 12.9 |
| El ordenador de la farmacia no funcionaba | 9.0 |
| Estaba fuera de plazo (era demasiado pronto o demasiado tarde) | 29.3 |
| No aparecían los medicamentos recetados | 22.3 |
| No pudo retirarlos en una comunidad autónoma distinta a la suya | 6.6 |
| Otro tipo de problema | 18.8 |
| No recuerda | |
| N.C. | 1.2 |
2.4.1.3 Tablas combinadas
Con las múltiples también funciona el posicionamiento del estadístico casos -frecuencias- cuando combinamos los mismos (frecuencia y porcentaje) y podemos realizar las mismas variantes que antes.
Ubicar los cálculos dentro de las columnas …
data %>%
tab_cells(mdset_f(P18C)) %>% # o tab_cells(mdset(P18C01 %to% P18C08))
tab_stat_cases(label ="Casos") %>%
tab_stat_cpct(label="% casos") %>%
tab_stat_cpct_responses(label="% respuestas") %>%
tab_pivot(stat_position="inside_columns")| #Total | |||
|---|---|---|---|
| Casos | % casos | % respuestas | |
| La tarjeta sanitaria no funcionaba | 33 | 16.7 | 12.9 |
| El ordenador de la farmacia no funcionaba | 23 | 11.6 | 9.0 |
| Estaba fuera de plazo (era demasiado pronto o demasiado tarde) | 75 | 37.9 | 29.3 |
| No aparecían los medicamentos recetados | 57 | 28.8 | 22.3 |
| No pudo retirarlos en una comunidad autónoma distinta a la suya | 17 | 8.6 | 6.6 |
| Otro tipo de problema | 48 | 24.2 | 18.8 |
| No recuerda | |||
| N.C. | 3 | 1.5 | 1.2 |
| #Total responses | 256 | ||
| #Total cases | 198 | 198 | |
Préstese atención a las dos líneas de #Total, dado que las bases son diferentes (número de individuos y número de respuestas).
Podemos ubicar los cálculos dentro de las filas …
data %>%
tab_cells(mdset_f(P18C)) %>% # o tab_cells(mdset(P18C01 %to% P18C08))
tab_stat_cases(label ="Casos") %>%
tab_stat_cpct(label="% casos") %>%
tab_stat_cpct_responses(label="% respuestas") %>%
tab_pivot(stat_position="inside_rows")| #Total | |
|---|---|
| La tarjeta sanitaria no funcionaba | |
| Casos | 33.0 |
| % casos | 16.7 |
| % respuestas | 12.9 |
| El ordenador de la farmacia no funcionaba | |
| Casos | 23.0 |
| % casos | 11.6 |
| % respuestas | 9.0 |
| Estaba fuera de plazo (era demasiado pronto o demasiado tarde) | |
| Casos | 75.0 |
| % casos | 37.9 |
| % respuestas | 29.3 |
| No aparecían los medicamentos recetados | |
| Casos | 57.0 |
| % casos | 28.8 |
| % respuestas | 22.3 |
| No pudo retirarlos en una comunidad autónoma distinta a la suya | |
| Casos | 17.0 |
| % casos | 8.6 |
| % respuestas | 6.6 |
| Otro tipo de problema | |
| Casos | 48.0 |
| % casos | 24.2 |
| % respuestas | 18.8 |
| No recuerda | |
| Casos | |
| % casos | |
| % respuestas | |
| N.C. | |
| Casos | 3.0 |
| % casos | 1.5 |
| % respuestas | 1.2 |
| #Total cases | |
| Casos | 198 |
| % casos | 198 |
| #Total responses | |
| % respuestas | 256 |
Podemos ubicar los cálculos fuera de las columnas (igual a la anterior inside... porque no hay campo de columna) …
data %>%
tab_cells(mdset_f(P18C)) %>% # o tab_cells(mdset(P18C01 %to% P18C08))
tab_stat_cases(label ="Casos") %>%
tab_stat_cpct(label="% casos") %>%
tab_stat_cpct_responses(label="% respuestas") %>%
tab_pivot(stat_position="outside_columns")| #Total | |||
|---|---|---|---|
| Casos | % casos | % respuestas | |
| La tarjeta sanitaria no funcionaba | 33 | 16.7 | 12.9 |
| El ordenador de la farmacia no funcionaba | 23 | 11.6 | 9.0 |
| Estaba fuera de plazo (era demasiado pronto o demasiado tarde) | 75 | 37.9 | 29.3 |
| No aparecían los medicamentos recetados | 57 | 28.8 | 22.3 |
| No pudo retirarlos en una comunidad autónoma distinta a la suya | 17 | 8.6 | 6.6 |
| Otro tipo de problema | 48 | 24.2 | 18.8 |
| No recuerda | |||
| N.C. | 3 | 1.5 | 1.2 |
| #Total responses | 256 | ||
| #Total cases | 198 | 198 | |
Podemos ubicar los cálculos fuera de las filas; nótese que la agrupación es diferente a la anterior con inside_rows...
data %>%
tab_cells(mdset_f(P18C)) %>% # o tab_cells(mdset(P18C01 %to% P18C08))
tab_stat_cases(label ="Casos") %>%
tab_stat_cpct(label="% casos") %>%
tab_stat_cpct_responses(label="% respuestas") %>%
tab_pivot(stat_position="outside_rows")| #Total | |
|---|---|
| La tarjeta sanitaria no funcionaba | |
| Casos | 33.0 |
| El ordenador de la farmacia no funcionaba | |
| Casos | 23.0 |
| Estaba fuera de plazo (era demasiado pronto o demasiado tarde) | |
| Casos | 75.0 |
| No aparecían los medicamentos recetados | |
| Casos | 57.0 |
| No pudo retirarlos en una comunidad autónoma distinta a la suya | |
| Casos | 17.0 |
| Otro tipo de problema | |
| Casos | 48.0 |
| No recuerda | |
| Casos | |
| N.C. | |
| Casos | 3.0 |
| #Total cases | |
| Casos | 198 |
| La tarjeta sanitaria no funcionaba | |
| % casos | 16.7 |
| El ordenador de la farmacia no funcionaba | |
| % casos | 11.6 |
| Estaba fuera de plazo (era demasiado pronto o demasiado tarde) | |
| % casos | 37.9 |
| No aparecían los medicamentos recetados | |
| % casos | 28.8 |
| No pudo retirarlos en una comunidad autónoma distinta a la suya | |
| % casos | 8.6 |
| Otro tipo de problema | |
| % casos | 24.2 |
| No recuerda | |
| % casos | |
| N.C. | |
| % casos | 1.5 |
| #Total cases | |
| % casos | 198 |
| La tarjeta sanitaria no funcionaba | |
| % respuestas | 12.9 |
| El ordenador de la farmacia no funcionaba | |
| % respuestas | 9.0 |
| Estaba fuera de plazo (era demasiado pronto o demasiado tarde) | |
| % respuestas | 29.3 |
| No aparecían los medicamentos recetados | |
| % respuestas | 22.3 |
| No pudo retirarlos en una comunidad autónoma distinta a la suya | |
| % respuestas | 6.6 |
| Otro tipo de problema | |
| % respuestas | 18.8 |
| No recuerda | |
| % respuestas | |
| N.C. | |
| % respuestas | 1.2 |
| #Total responses | |
| % respuestas | 256 |
2.4.2 Estadísticos
Hasta ahora hemos trabajado sólo con casos, pero ya hemos anticipado que al igual que con los recuentos de casos o frecuencias se puede trabajar con otros estadísticos como la suma, máximo, mínimo, media, mediana, error estándar y desviación típica. Vamos a ir viendo cómo se desarrollan estos cuadros.
2.4.2.1 Estadísticos básicos
Recordemos que hasta ahora no hemos cruzado la información, solo estamos trabajando con lo que se denomina medidas marginales.Nuestro primer ejemplo es un caso típico, donde queremos obtener la media (tab_stat_mean), la desviación típica (tab_stat_sd()) y la base de cálculo, es decir el número de casos con valor (tab_stat_valid_n()) para el cálculo.
Así, siguiendo la misma estructura de las tablas anteriores, redactamos el siguiente script:
data %>%
tab_cells(P3) %>%
tab_stat_mean() %>%
tab_stat_sd() %>%
tab_stat_valid_n() %>%
tab_pivot()| #Total | |
|---|---|
| Escala de satisfacción (1-10) con el funcionamiento del sistema sanitario español | |
| Mean | 7.3 |
| Std. dev. | 7.2 |
| Valid N | 2557.0 |
No, no tienes por qué ver los nombres de los estadísticos en lengua inglesa. También aquí podemos jugar con la etiqueta (label).
data %>%
tab_cells(P3) %>%
tab_stat_mean(label = 'media') %>%
tab_stat_sd(label = 'desviación') %>%
tab_stat_valid_n(label = 'casos') %>%
tab_pivot()| #Total | |
|---|---|
| Escala de satisfacción (1-10) con el funcionamiento del sistema sanitario español | |
| media | 7.3 |
| desviación | 7.2 |
| casos | 2557.0 |
Hagamos una nueva tabla con una pequeña variación, ahora vamos a poner los estadísticos en columnas.
data%>%
tab_cells(P3) %>%
tab_stat_mean(label = 'media') %>%
tab_stat_sd(label = 'desviación') %>%
tab_stat_valid_n(label = 'casos') %>%
tab_pivot(stat_position = "inside_columns")| #Total | |||
|---|---|---|---|
| media | desviación | casos | |
| Escala de satisfacción (1-10) con el funcionamiento del sistema sanitario español | 7.3 | 7.2 | 2557 |
expss tiene además la posibilidad de obtener estos tres cálculos, bastante habituales por cierto, con un solo comando: tab_stat_mean_sd_n() pudiendo añadir además etiquetas separadas.
data %>%
tab_cells(P3) %>%
tab_stat_mean_sd_n(labels = c("media", "desviación", "casos")) %>%
tab_pivot()| #Total | |
|---|---|
| Escala de satisfacción (1-10) con el funcionamiento del sistema sanitario español | |
| media | 7.3 |
| desviación | 7.2 |
| casos | 2557.0 |
2.4.2.2 Otros estadísticos
Además de los estadísticos más básicos, otros que podemos añadir son el máximo, el mínimo, la mediana, el error estándar y la suma. Los unimos todos.
data %>%
tab_cells(P3) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_stat_max(label = "Máximo") %>%
tab_stat_min(label = "Mínimo") %>%
tab_stat_median(label = "Mediana") %>%
tab_stat_se(label = "Error estándar") %>%
tab_stat_sum(label = "Suma") %>%
tab_pivot()| #Total | |
|---|---|
| Escala de satisfacción (1-10) con el funcionamiento del sistema sanitario español | |
| Media | 7.3 |
| Desviación | 7.2 |
| Máximo | 99.0 |
| Mínimo | 1.0 |
| Mediana | 7.0 |
| Error estándar | 0.1 |
| Suma | 18789.0 |
Nótese que no se han definido ni filas, ni columnas. Es el modificador de la posición de los estadísticos (stat_position) el que habilita la posición en una fila.
Del mismo modo, estos estadísticos pueden ubicarse en las columnas.
data %>%
tab_cells(P3) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_stat_max(label = "Máximo") %>%
tab_stat_min(label = "Mínimo") %>%
tab_stat_median(label = "Mediana") %>%
tab_stat_se(label = "Error estándar") %>%
tab_stat_sum(label = "Suma") %>%
tab_pivot(stat_position = "inside_columns")| #Total | |||||||
|---|---|---|---|---|---|---|---|
| Media | Desviación | Máximo | Mínimo | Mediana | Error estándar | Suma | |
| Escala de satisfacción (1-10) con el funcionamiento del sistema sanitario español | 7.3 | 7.2 | 99 | 1 | 7 | 0.1 | 18789 |
Hagamos finalmente una leve variación. Nótese que al utilizar '|'en la etiqueta del estadístico casos, hemos eliminado la columna intermedia y aparece todo como más compacto. Este será un recurso que utilizaremos en muchas ocasiones.
data %>%
tab_cells(P3) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_stat_max(label = "Máximo") %>%
tab_stat_min(label = "Mínimo") %>%
tab_stat_median(label = "Mediana") %>%
tab_stat_se(label = "Error estándar") %>%
tab_stat_sum(label = "Suma") %>%
tab_stat_cases(label = "|") %>%
tab_pivot(stat_position = "inside_rows")| #Total | |
|---|---|
| Escala de satisfacción (1-10) con el funcionamiento del sistema sanitario español | |
| Media | 7.3 |
| Desviación | 7.2 |
| Máximo | 99.0 |
| Mínimo | 1.0 |
| Mediana | 7.0 |
| Error estándar | 0.1 |
| Suma | 18789.0 |
| 1 Muy insatisfecho/a | 40.0 |
| 2 | 35.0 |
| 3 | 75.0 |
| 4 | 111.0 |
| 5 | 295.0 |
| 6 | 397.0 |
| 7 | 584.0 |
| 8 | 623.0 |
| 9 | 210.0 |
| 10 Muy satisfecho/a | 172.0 |
| N.S. | 14.0 |
| N.C. | 1.0 |
| #Total cases | 2557 |
2.5 Tablas cruzadas
A diferencia de lo visto en el anterior capítulo, en este epígrafe analizaremos como obtener cuadros resumen en los que existen variables en la cabecera, que determinan grupos de análisis y existen variables en las filas, de las cuáles queremos conocer como se distribuyen sus alternativas de respuesta entre los diferentes perfiles o grupos que determinan las variables de columna. Al igual que sucedió con las tablas marginales, mostraremos poco a poco como trabajar con variables de respuesta simple, múltiple o con medidas estadísticas. Vamos a utilizar otros campos que se localizan en la base de datos del CIS (P3, P21A01, P21A02, P21A03, P31, P33).
2.5.1 Básica con variables simples
Las tablas que vamos a hacer a continuación, siempre son tablas en las que intervienen al menos dos variables. Una de las variables irá a columnas y la otra variable irá a filas. De ellas se calcularán las frecuencias absolutas o relativas y/o los estadísticos. Vamos a empezar sólo con el estadístico frecuencias, y posteriormente ya pasaremos a estadísticos como la media, suma, etc…
2.5.1.1 De frecuencias, variable simple y sólo absolutos
data %>%
tab_cells(P33) %>%
tab_cols(total(), P31) %>%
tab_stat_cases(total_row_position = "above",
total_label = "Total") %>%
tab_pivot()| #Total | Sexo de la persona entrevistada | |||
|---|---|---|---|---|
| Hombre | Mujer | |||
| Estado civil de la persona entrevistada | ||||
| #Total | 2557 | 1256 | 1301 | |
| Casado/a | 1388 | 677 | 711 | |
| Soltero/a | 817 | 455 | 362 | |
| Viudo/a | 190 | 41 | 149 | |
| Separado/a | 57 | 24 | 33 | |
| Divorciado/a | 97 | 55 | 42 | |
| N.C. | 8 | 4 | 4 | |
2.5.1.2 De frecuencias, variable simple, con porcentajes de columna
Al igual que hicimos con las tablas marginales vamos a repetir esta tabla, pero en porcentaje de columna (vertical).
data %>%
tab_cells(P33) %>%
tab_cols(total(), P31) %>%
tab_stat_cpct(total_row_position = "above",
total_label = "Total") %>% # aquí señalo los porcentajes de columna
tab_pivot()| #Total | Sexo de la persona entrevistada | |||
|---|---|---|---|---|
| Hombre | Mujer | |||
| Estado civil de la persona entrevistada | ||||
| #Total | 2557 | 1256 | 1301 | |
| Casado/a | 54.3 | 53.9 | 54.7 | |
| Soltero/a | 32.0 | 36.2 | 27.8 | |
| Viudo/a | 7.4 | 3.3 | 11.5 | |
| Separado/a | 2.2 | 1.9 | 2.5 | |
| Divorciado/a | 3.8 | 4.4 | 3.2 | |
| N.C. | 0.3 | 0.3 | 0.3 | |
2.5.1.3 De frecuencias, variable simple, con porcentajes de fila
Al igual que hicimos con las tablas marginales vamos a repetir esta tabla, pero en porcentaje de fila (horizontal).
data %>%
tab_cells(P33) %>%
tab_cols(total(), P31) %>%
tab_stat_rpct(total_row_position = "above",
total_label = "Total") %>% # aquí señalamos los porcentajes de fila
tab_pivot()| #Total | Sexo de la persona entrevistada | |||
|---|---|---|---|---|
| Hombre | Mujer | |||
| Estado civil de la persona entrevistada | ||||
| #Total | 2557 | 1256 | 1301 | |
| Casado/a | 100 | 48.8 | 51.2 | |
| Soltero/a | 100 | 55.7 | 44.3 | |
| Viudo/a | 100 | 21.6 | 78.4 | |
| Separado/a | 100 | 42.1 | 57.9 | |
| Divorciado/a | 100 | 56.7 | 43.3 | |
| N.C. | 100 | 50.0 | 50.0 | |
2.5.1.4 De frecuencias, variable simple, con porcentajes total muestra
Al igual que hicimos con las tablas marginales vamos a repetir esta tabla, pero en porcentaje sobre el total de la muestra.
data %>%
tab_cells(P33) %>%
tab_cols(total(), P31) %>%
tab_stat_tpct(total_row_position = "above",
total_label = "Total") %>% # aquí señalamos los porcentajes total muestra
tab_pivot()| #Total | Sexo de la persona entrevistada | |||
|---|---|---|---|---|
| Hombre | Mujer | |||
| Estado civil de la persona entrevistada | ||||
| #Total | 2557 | 1256 | 1301 | |
| Casado/a | 54.3 | 26.5 | 27.8 | |
| Soltero/a | 32.0 | 17.8 | 14.2 | |
| Viudo/a | 7.4 | 1.6 | 5.8 | |
| Separado/a | 2.2 | 0.9 | 1.3 | |
| Divorciado/a | 3.8 | 2.2 | 1.6 | |
| N.C. | 0.3 | 0.2 | 0.2 | |
2.5.1.5 Combinaciones de los anteriores
Vamos ahora a hacer combinaciones entre ellos. Advierto que cada vez se dificulta más la tabla en su lectura. Como dije inicialmente, me decanto más por tablas sencillas y con un sólo dato.
data %>%
tab_cells(P33) %>%
tab_cols(total(), P31) %>%
tab_stat_cases(label = "Casos") %>%
tab_stat_cpct(label = "% casos") %>%
tab_pivot(stat_position = "inside_columns")| #Total | Sexo de la persona entrevistada | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Casos | % casos | Hombre | Mujer | ||||||
| Casos | % casos | Casos | % casos | ||||||
| Estado civil de la persona entrevistada | |||||||||
| Casado/a | 1388 | 54.3 | 677 | 53.9 | 711 | 54.7 | |||
| Soltero/a | 817 | 32.0 | 455 | 36.2 | 362 | 27.8 | |||
| Viudo/a | 190 | 7.4 | 41 | 3.3 | 149 | 11.5 | |||
| Separado/a | 57 | 2.2 | 24 | 1.9 | 33 | 2.5 | |||
| Divorciado/a | 97 | 3.8 | 55 | 4.4 | 42 | 3.2 | |||
| N.C. | 8 | 0.3 | 4 | 0.3 | 4 | 0.3 | |||
| #Total cases | 2557 | 2557 | 1256 | 1256 | 1301 | 1301 | |||
Y la misma tabla pero con los estadísticos en las filas combinando frecuencia y porcentaje…
data %>%
tab_cells(P33) %>%
tab_cols(total(), P31) %>%
tab_stat_cases(label = "Casos") %>%
tab_stat_cpct(label = "% casos") %>%
tab_pivot(stat_position = "outside_columns")| #Total | Sexo de la persona entrevistada | #Total | Sexo de la persona entrevistada | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Casos | Hombre | Mujer | % casos | Hombre | Mujer | ||||||
| Casos | Casos | % casos | % casos | ||||||||
| Estado civil de la persona entrevistada | |||||||||||
| Casado/a | 1388 | 677 | 711 | 54.3 | 53.9 | 54.7 | |||||
| Soltero/a | 817 | 455 | 362 | 32.0 | 36.2 | 27.8 | |||||
| Viudo/a | 190 | 41 | 149 | 7.4 | 3.3 | 11.5 | |||||
| Separado/a | 57 | 24 | 33 | 2.2 | 1.9 | 2.5 | |||||
| Divorciado/a | 97 | 55 | 42 | 3.8 | 4.4 | 3.2 | |||||
| N.C. | 8 | 4 | 4 | 0.3 | 0.3 | 0.3 | |||||
| #Total cases | 2557 | 1256 | 1301 | 2557 | 1256 | 1301 | |||||
Y la misma tabla pero con los estadísticos en las filas combinando frecuencia y porcentaje…
data %>%
tab_cells(P33) %>%
tab_cols(total(), P31) %>%
tab_stat_cases(label = "Casos") %>%
tab_stat_cpct(label = "% casos") %>%
tab_pivot(stat_position = "inside_rows")| #Total | Sexo de la persona entrevistada | |||||
|---|---|---|---|---|---|---|
| Hombre | Mujer | |||||
| Estado civil de la persona entrevistada | ||||||
| Casado/a | Casos | 1388.0 | 677.0 | 711.0 | ||
| % casos | 54.3 | 53.9 | 54.7 | |||
| Soltero/a | Casos | 817.0 | 455.0 | 362.0 | ||
| % casos | 32.0 | 36.2 | 27.8 | |||
| Viudo/a | Casos | 190.0 | 41.0 | 149.0 | ||
| % casos | 7.4 | 3.3 | 11.5 | |||
| Separado/a | Casos | 57.0 | 24.0 | 33.0 | ||
| % casos | 2.2 | 1.9 | 2.5 | |||
| Divorciado/a | Casos | 97.0 | 55.0 | 42.0 | ||
| % casos | 3.8 | 4.4 | 3.2 | |||
| N.C. | Casos | 8.0 | 4.0 | 4.0 | ||
| % casos | 0.3 | 0.3 | 0.3 | |||
| #Total cases | Casos | 2557 | 1256 | 1301 | ||
| % casos | 2557 | 1256 | 1301 | |||
Y la misma tabla pero con los estadísticos en las filas por bloque de tipo de estadístico…
data %>%
tab_cells(P33) %>%
tab_cols(total(), P31) %>%
tab_stat_cases(label = "Casos") %>%
tab_stat_cpct(label = "% casos") %>%
tab_pivot(stat_position = "outside_rows")| #Total | Sexo de la persona entrevistada | |||||
|---|---|---|---|---|---|---|
| Hombre | Mujer | |||||
| Estado civil de la persona entrevistada | ||||||
| Casado/a | Casos | 1388.0 | 677.0 | 711.0 | ||
| Soltero/a | Casos | 817.0 | 455.0 | 362.0 | ||
| Viudo/a | Casos | 190.0 | 41.0 | 149.0 | ||
| Separado/a | Casos | 57.0 | 24.0 | 33.0 | ||
| Divorciado/a | Casos | 97.0 | 55.0 | 42.0 | ||
| N.C. | Casos | 8.0 | 4.0 | 4.0 | ||
| #Total cases | Casos | 2557 | 1256 | 1301 | ||
| Casado/a | % casos | 54.3 | 53.9 | 54.7 | ||
| Soltero/a | % casos | 32.0 | 36.2 | 27.8 | ||
| Viudo/a | % casos | 7.4 | 3.3 | 11.5 | ||
| Separado/a | % casos | 2.2 | 1.9 | 2.5 | ||
| Divorciado/a | % casos | 3.8 | 4.4 | 3.2 | ||
| N.C. | % casos | 0.3 | 0.3 | 0.3 | ||
| #Total cases | % casos | 2557 | 1256 | 1301 | ||
2.5.2 Básica con múltiples
Vamos a realizar ahora el mismo conjunto de tablas, pero en las filas, en lugar de una variable de tipo simple, vamos a utilizar una variable de tipo múltiple. Repetimos los cruces pero cambiamos las celdas donde ahora usaremos la variable P21A con la instrucción tab_cells(mdset(P21A01 %to% P21A03)).
2.5.2.1 De frecuencias, variable múltiple y sólo absolutos
data %>%
tab_cells(mdset(P21A01 %to% P21A03)) %>%
tab_cols(total(), P31) %>%
tab_stat_cases(total_row_position = "above",
total_label = "Total") %>%
tab_pivot()| #Total | Sexo de la persona entrevistada | |||
|---|---|---|---|---|
| Hombre | Mujer | |||
| #Total | 415 | 206 | 209 | |
| Medicamentos que recetan por adelantado (para que no falten) | 225 | 108 | 117 | |
| Envases que han quedado sin usar porque cambiaron el tratamiento | 136 | 70 | 66 | |
| Medicamentos que decidió no tomar | 82 | 42 | 40 | |
2.5.2.2 De frecuencias, variable múltiple, con porcentajes de columna
Al igual que hicimos con las tablas marginales vamos a repetir esta tabla, pero en porcentaje de columna (vertical).
data %>%
tab_cells(mdset(P21A01 %to% P21A03)) %>%
tab_cols(total(), P31) %>%
tab_stat_cpct(total_row_position = "above",
total_label = "Total") %>% # aquí señalamos los porcentajes de columna
tab_pivot()| #Total | Sexo de la persona entrevistada | |||
|---|---|---|---|---|
| Hombre | Mujer | |||
| #Total | 415 | 206 | 209 | |
| Medicamentos que recetan por adelantado (para que no falten) | 54.2 | 52.4 | 56.0 | |
| Envases que han quedado sin usar porque cambiaron el tratamiento | 32.8 | 34.0 | 31.6 | |
| Medicamentos que decidió no tomar | 19.8 | 20.4 | 19.1 | |
2.5.2.3 De frecuencias, variable múltiple, con porcentajes de fila
Al igual que hicimos con las tablas marginales vamos a repetir esta tabla, pero en porcentaje de fila (horizontal).
data %>%
tab_cells(mdset(P21A01 %to% P21A03)) %>%
tab_cols(total(), P31) %>%
tab_stat_rpct(total_row_position = "above",
total_label = "Total") %>% # aquí señalamos los porcentajes de fila
tab_pivot()| #Total | Sexo de la persona entrevistada | |||
|---|---|---|---|---|
| Hombre | Mujer | |||
| #Total | 415 | 206 | 209 | |
| Medicamentos que recetan por adelantado (para que no falten) | 100 | 48.0 | 52.0 | |
| Envases que han quedado sin usar porque cambiaron el tratamiento | 100 | 51.5 | 48.5 | |
| Medicamentos que decidió no tomar | 100 | 51.2 | 48.8 | |
2.5.2.4 De frecuencias, variable múltiple, con porcentajes total muestra
Al igual que hicimos con las tablas marginales vamos a repetir esta tabla, pero en porcentaje sobre el total de la muestra.
data %>%
tab_cells(mdset(P21A01 %to% P21A03)) %>%
tab_cols(total(), P31) %>%
tab_stat_tpct(total_row_position = "above",
total_label = "Total") %>% # aquí señalamos los porcentajes total muestra
tab_pivot()| #Total | Sexo de la persona entrevistada | |||
|---|---|---|---|---|
| Hombre | Mujer | |||
| #Total | 415 | 206 | 209 | |
| Medicamentos que recetan por adelantado (para que no falten) | 54.2 | 26.0 | 28.2 | |
| Envases que han quedado sin usar porque cambiaron el tratamiento | 32.8 | 16.9 | 15.9 | |
| Medicamentos que decidió no tomar | 19.8 | 10.1 | 9.6 | |
2.5.2.5 Combinaciones de los anteriores
Vamos ahora a hacer combinaciones entre ellos. Advierto que cada vez se dificulta más la tabla en su lectura. Como dije inicialmente, me decanto más por tablas sencillas y con un sólo dato.
data %>%
tab_cells(mdset(P21A01 %to% P21A03)) %>%
tab_cols(total(), P31) %>%
tab_stat_cases(label = "Casos") %>%
tab_stat_cpct(label = "% casos") %>%
tab_pivot(stat_position = "inside_columns")| #Total | Sexo de la persona entrevistada | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Casos | % casos | Hombre | Mujer | ||||||
| Casos | % casos | Casos | % casos | ||||||
| Medicamentos que recetan por adelantado (para que no falten) | 225 | 54.2 | 108 | 52.4 | 117 | 56.0 | |||
| Envases que han quedado sin usar porque cambiaron el tratamiento | 136 | 32.8 | 70 | 34.0 | 66 | 31.6 | |||
| Medicamentos que decidió no tomar | 82 | 19.8 | 42 | 20.4 | 40 | 19.1 | |||
| #Total cases | 415 | 415 | 206 | 206 | 209 | 209 | |||
Y la misma tabla pero con los estadísticos en las filas combinando frecuencia y porcentaje…
data %>%
tab_cells(mdset(P21A01 %to% P21A03)) %>%
tab_cols(total(), P31) %>%
tab_stat_cases(label = "Casos") %>%
tab_stat_cpct(label = "% casos") %>%
tab_pivot(stat_position = "outside_columns")| #Total | Sexo de la persona entrevistada | #Total | Sexo de la persona entrevistada | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Casos | Hombre | Mujer | % casos | Hombre | Mujer | ||||||
| Casos | Casos | % casos | % casos | ||||||||
| Medicamentos que recetan por adelantado (para que no falten) | 225 | 108 | 117 | 54.2 | 52.4 | 56.0 | |||||
| Envases que han quedado sin usar porque cambiaron el tratamiento | 136 | 70 | 66 | 32.8 | 34.0 | 31.6 | |||||
| Medicamentos que decidió no tomar | 82 | 42 | 40 | 19.8 | 20.4 | 19.1 | |||||
| #Total cases | 415 | 206 | 209 | 415 | 206 | 209 | |||||
Y la misma tabla pero con los estadísticos en las filas combinando frecuencia y porcentaje…
data %>%
tab_cells(mdset(P21A01 %to% P21A03)) %>%
tab_cols(total(), P31) %>%
tab_stat_cases(label = "Casos") %>%
tab_stat_cpct(label = "% casos") %>%
tab_pivot(stat_position = "inside_rows")| #Total | Sexo de la persona entrevistada | |||
|---|---|---|---|---|
| Hombre | Mujer | |||
| Medicamentos que recetan por adelantado (para que no falten) | ||||
| Casos | 225.0 | 108.0 | 117.0 | |
| % casos | 54.2 | 52.4 | 56.0 | |
| Envases que han quedado sin usar porque cambiaron el tratamiento | ||||
| Casos | 136.0 | 70.0 | 66.0 | |
| % casos | 32.8 | 34.0 | 31.6 | |
| Medicamentos que decidió no tomar | ||||
| Casos | 82.0 | 42.0 | 40.0 | |
| % casos | 19.8 | 20.4 | 19.1 | |
| #Total cases | ||||
| Casos | 415 | 206 | 209 | |
| % casos | 415 | 206 | 209 | |
Y la misma tabla pero con los estadísticos en las filas por bloque de tipo de estadístico…
data %>%
tab_cells(mdset(P21A01 %to% P21A03)) %>%
tab_cols(total(), P31) %>%
tab_stat_cases(label = "Casos") %>%
tab_stat_cpct(label = "% casos") %>%
tab_pivot(stat_position = "outside_rows")| #Total | Sexo de la persona entrevistada | |||
|---|---|---|---|---|
| Hombre | Mujer | |||
| Medicamentos que recetan por adelantado (para que no falten) | ||||
| Casos | 225.0 | 108.0 | 117.0 | |
| Envases que han quedado sin usar porque cambiaron el tratamiento | ||||
| Casos | 136.0 | 70.0 | 66.0 | |
| Medicamentos que decidió no tomar | ||||
| Casos | 82.0 | 42.0 | 40.0 | |
| #Total cases | ||||
| Casos | 415 | 206 | 209 | |
| Medicamentos que recetan por adelantado (para que no falten) | ||||
| % casos | 54.2 | 52.4 | 56.0 | |
| Envases que han quedado sin usar porque cambiaron el tratamiento | ||||
| % casos | 32.8 | 34.0 | 31.6 | |
| Medicamentos que decidió no tomar | ||||
| % casos | 19.8 | 20.4 | 19.1 | |
| #Total cases | ||||
| % casos | 415 | 206 | 209 | |
Recordamos que siempre con las múltiples existe la posibilidad de calcular los porcentajes con base respuesta en lugar de con base cuestionario (individuos). Para ello debes utilizar tab_stat_cpct_responses().
2.5.3 Básica con estadísticos
Del mismo modo que antes utilizábamos la tabla cruzada para obtener los casos de intersección entre las categorías de columna y las categorías de fila, ahora procederemos a hacer lo mismo pero con categorías en columnas y cálculo de estadísticos básicos en otro. En definitiva, calcular las medidas estadísticas para cada grupo creado por la variable que general las categorías.
2.5.3.1 Cruce entre variable simple y dos estadísticos
Vamos a comenzar con las más simples, dos estadísticos (media y desviación) de una variable métrica (P3) calculados para una variable (P31) que genera dos categorías (hombre y mujer). Nótese el juego a realizar con más de 2 estadísticos con la ubicación de los mismos.
data %>%
tab_cells(P3) %>%
tab_cols(total(), P31) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot()| #Total | Sexo de la persona entrevistada | |||
|---|---|---|---|---|
| Hombre | Mujer | |||
| Escala de satisfacción (1-10) con el funcionamiento del sistema sanitario español | ||||
| Media | 7.3 | 7.3 | 7.4 | |
| Desviación | 7.2 | 6.6 | 7.8 | |
Hagamos ahora su traspuesta, es decir ubiquemos en filas P31 y en columnas
var_lab(data$P3)="Satisfacción"
data %>%
tab_cells(P3) %>%
tab_rows(total(),P31) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot()| #Total | |||
|---|---|---|---|
| #Total | |||
| Satisfacción | Media | 7.3 | |
| Sexo de la persona entrevistada | |||
| Hombre | Satisfacción | Media | 7.3 |
| Mujer | Satisfacción | Media | 7.4 |
| #Total | |||
| Satisfacción | Desviación | 7.2 | |
| Sexo de la persona entrevistada | |||
| Hombre | Satisfacción | Desviación | 6.6 |
| Mujer | Satisfacción | Desviación | 7.8 |
Recordemos que los estadísticos los podemos ir moviendo a nuestra necesidad para que se organicen de una forma u otra…
Dentro de las columnas …
data %>%
tab_cells(P3) %>%
tab_cols(total(), P31) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot(stat_position = "inside_columns")| #Total | Sexo de la persona entrevistada | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Media | Desviación | Hombre | Mujer | ||||||
| Media | Desviación | Media | Desviación | ||||||
| Satisfacción | 7.3 | 7.2 | 7.3 | 6.6 | 7.4 | 7.8 | |||
Dentro de las filas …
data %>%
tab_cells(P3) %>%
tab_cols(total(), P31) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot(stat_position = "inside_rows")| #Total | Sexo de la persona entrevistada | |||
|---|---|---|---|---|
| Hombre | Mujer | |||
| Satisfacción | ||||
| Media | 7.3 | 7.3 | 7.4 | |
| Desviación | 7.2 | 6.6 | 7.8 | |
Como columnas separadas o fuera de columnas …
data %>%
tab_cells(P3) %>%
tab_cols(total(), P31) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot(stat_position = "outside_columns")| #Total | Sexo de la persona entrevistada | #Total | Sexo de la persona entrevistada | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Media | Hombre | Mujer | Desviación | Hombre | Mujer | ||||||
| Media | Media | Desviación | Desviación | ||||||||
| Satisfacción | 7.3 | 7.3 | 7.4 | 7.2 | 6.6 | 7.8 | |||||
Como filas separadas o fuera de filas…
data %>%
tab_cells(P3) %>%
tab_cols(total(), P31) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot(stat_position = "outside_rows")| #Total | Sexo de la persona entrevistada | |||
|---|---|---|---|---|
| Hombre | Mujer | |||
| Satisfacción | ||||
| Media | 7.3 | 7.3 | 7.4 | |
| Desviación | 7.2 | 6.6 | 7.8 | |
Repitamos ahora estas cuatro últimas tablas, pero en lugar de con una variable que genera grupos y de ellos se calcula la medida estadística, vamos a hacerlo con un cruce de categorías (un campo en columnas y otro en filas) y que en esos cruces, se calcule la medida estadística. Por ejemplo esta tabla me permitiría saber la media de P3 en los hombres de 18 a 25 años.
data %>%
tab_cells(P3) %>%
tab_cols(total(), P31) %>%
tab_rows(P33) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot()| #Total | Sexo de la persona entrevistada | ||||||
|---|---|---|---|---|---|---|---|
| Hombre | Mujer | ||||||
| Estado civil de la persona entrevistada | |||||||
| Casado/a | Satisfacción | Media | 7.3 | 7.5 | 7.2 | ||
| Soltero/a | Satisfacción | Media | 7.2 | 6.9 | 7.4 | ||
| Viudo/a | Satisfacción | Media | 7.9 | 7.2 | 8.1 | ||
| Separado/a | Satisfacción | Media | 6.7 | 6.5 | 6.9 | ||
| Divorciado/a | Satisfacción | Media | 7.5 | 8.3 | 6.3 | ||
| N.C. | Satisfacción | Media | 18.2 | 7.5 | 29.0 | ||
| Casado/a | Satisfacción | Desviación | 6.7 | 7.2 | 6.2 | ||
| Soltero/a | Satisfacción | Desviación | 7.4 | 4.6 | 9.8 | ||
| Viudo/a | Satisfacción | Desviación | 6.9 | 2.3 | 7.7 | ||
| Separado/a | Satisfacción | Desviación | 2.1 | 2.5 | 1.8 | ||
| Divorciado/a | Satisfacción | Desviación | 9.5 | 12.5 | 2.3 | ||
| N.C. | Satisfacción | Desviación | 32.3 | 2.4 | 46.0 | ||
y juguemos con la posición del cálculo estadística que ahora sí arrojará cuatro configuraciones diferentes.
La primera con los estadísticos fuera de las filas…
data %>%
tab_cells(P3) %>%
tab_cols(total(), P31) %>%
tab_rows(P33) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot(stat_position = "outside_rows") # por defecto, sin lo ponemos muestra esta opción| #Total | Sexo de la persona entrevistada | ||||||
|---|---|---|---|---|---|---|---|
| Hombre | Mujer | ||||||
| Estado civil de la persona entrevistada | |||||||
| Casado/a | Satisfacción | Media | 7.3 | 7.5 | 7.2 | ||
| Soltero/a | Satisfacción | Media | 7.2 | 6.9 | 7.4 | ||
| Viudo/a | Satisfacción | Media | 7.9 | 7.2 | 8.1 | ||
| Separado/a | Satisfacción | Media | 6.7 | 6.5 | 6.9 | ||
| Divorciado/a | Satisfacción | Media | 7.5 | 8.3 | 6.3 | ||
| N.C. | Satisfacción | Media | 18.2 | 7.5 | 29.0 | ||
| Casado/a | Satisfacción | Desviación | 6.7 | 7.2 | 6.2 | ||
| Soltero/a | Satisfacción | Desviación | 7.4 | 4.6 | 9.8 | ||
| Viudo/a | Satisfacción | Desviación | 6.9 | 2.3 | 7.7 | ||
| Separado/a | Satisfacción | Desviación | 2.1 | 2.5 | 1.8 | ||
| Divorciado/a | Satisfacción | Desviación | 9.5 | 12.5 | 2.3 | ||
| N.C. | Satisfacción | Desviación | 32.3 | 2.4 | 46.0 | ||
Los estadísticos dentro de las filas …
data %>%
tab_cells(P3) %>%
tab_cols(total(), P31) %>%
tab_rows(P33) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot(stat_position = "inside_rows")| #Total | Sexo de la persona entrevistada | ||||||
|---|---|---|---|---|---|---|---|
| Hombre | Mujer | ||||||
| Estado civil de la persona entrevistada | |||||||
| Casado/a | Satisfacción | Media | 7.3 | 7.5 | 7.2 | ||
| Desviación | 6.7 | 7.2 | 6.2 | ||||
| Soltero/a | Satisfacción | Media | 7.2 | 6.9 | 7.4 | ||
| Desviación | 7.4 | 4.6 | 9.8 | ||||
| Viudo/a | Satisfacción | Media | 7.9 | 7.2 | 8.1 | ||
| Desviación | 6.9 | 2.3 | 7.7 | ||||
| Separado/a | Satisfacción | Media | 6.7 | 6.5 | 6.9 | ||
| Desviación | 2.1 | 2.5 | 1.8 | ||||
| Divorciado/a | Satisfacción | Media | 7.5 | 8.3 | 6.3 | ||
| Desviación | 9.5 | 12.5 | 2.3 | ||||
| N.C. | Satisfacción | Media | 18.2 | 7.5 | 29.0 | ||
| Desviación | 32.3 | 2.4 | 46.0 | ||||
Los estadísticos dentro de las columnas …
data %>%
tab_cells(P3) %>%
tab_cols(total(), P31) %>%
tab_rows(P33) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot(stat_position = "inside_columns")| #Total | Sexo de la persona entrevistada | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Media | Desviación | Hombre | Mujer | ||||||||
| Media | Desviación | Media | Desviación | ||||||||
| Estado civil de la persona entrevistada | |||||||||||
| Casado/a | Satisfacción | 7.3 | 6.7 | 7.5 | 7.2 | 7.2 | 6.2 | ||||
| Soltero/a | Satisfacción | 7.2 | 7.4 | 6.9 | 4.6 | 7.4 | 9.8 | ||||
| Viudo/a | Satisfacción | 7.9 | 6.9 | 7.2 | 2.3 | 8.1 | 7.7 | ||||
| Separado/a | Satisfacción | 6.7 | 2.1 | 6.5 | 2.5 | 6.9 | 1.8 | ||||
| Divorciado/a | Satisfacción | 7.5 | 9.5 | 8.3 | 12.5 | 6.3 | 2.3 | ||||
| N.C. | Satisfacción | 18.2 | 32.3 | 7.5 | 2.4 | 29.0 | 46.0 | ||||
Los estadísticos fuera de las columnas …
data %>%
tab_cells(P3) %>%
tab_cols(total(), P31) %>%
tab_rows(P33) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot(stat_position = "outside_columns")| #Total | Sexo de la persona entrevistada | #Total | Sexo de la persona entrevistada | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Media | Hombre | Mujer | Desviación | Hombre | Mujer | ||||||||
| Media | Media | Desviación | Desviación | ||||||||||
| Estado civil de la persona entrevistada | |||||||||||||
| Casado/a | Satisfacción | 7.3 | 7.5 | 7.2 | 6.7 | 7.2 | 6.2 | ||||||
| Soltero/a | Satisfacción | 7.2 | 6.9 | 7.4 | 7.4 | 4.6 | 9.8 | ||||||
| Viudo/a | Satisfacción | 7.9 | 7.2 | 8.1 | 6.9 | 2.3 | 7.7 | ||||||
| Separado/a | Satisfacción | 6.7 | 6.5 | 6.9 | 2.1 | 2.5 | 1.8 | ||||||
| Divorciado/a | Satisfacción | 7.5 | 8.3 | 6.3 | 9.5 | 12.5 | 2.3 | ||||||
| N.C. | Satisfacción | 18.2 | 7.5 | 29.0 | 32.3 | 2.4 | 46.0 | ||||||
¿Hacemos lo mismo para una variable múltiple?
2.5.3.1.1 Tabulación cruzada (con cálculo estadístico) y múltiples
Vamos a comenzar con las más simples, dos estadísticos (media y desviación) de una variable métrica (P3) calculados para una variable múltiple (P4_1 a P4_3) que genera categorías. Nótese el juego a realizar con más de 2 estadísticos con la ubicación de los mismos.
data %>%
tab_cells(P3) %>%
tab_cols(total(), mdset(P21A01 %to% P21A03)) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot()| #Total | Medicamentos que recetan por adelantado (para que no falten) | Envases que han quedado sin usar porque cambiaron el tratamiento | Medicamentos que decidió no tomar | |
|---|---|---|---|---|
| Satisfacción | ||||
| Media | 7.3 | 7.2 | 6.9 | 6.7 |
| Desviación | 7.2 | 6.4 | 1.5 | 1.7 |
Hagamos ahora su traspuesta, es decir ubiquemos en filas P21A y en columnas P3.
data %>%
tab_cells(P3) %>%
tab_rows(total(),mdset(P21A01 %to% P21A03)) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot()| #Total | ||
|---|---|---|
| #Total | ||
| Satisfacción | Media | 7.3 |
| Medicamentos que recetan por adelantado (para que no falten) | ||
| Satisfacción | Media | 7.2 |
| Envases que han quedado sin usar porque cambiaron el tratamiento | ||
| Satisfacción | Media | 6.9 |
| Medicamentos que decidió no tomar | ||
| Satisfacción | Media | 6.7 |
| #Total | ||
| Satisfacción | Desviación | 7.2 |
| Medicamentos que recetan por adelantado (para que no falten) | ||
| Satisfacción | Desviación | 6.4 |
| Envases que han quedado sin usar porque cambiaron el tratamiento | ||
| Satisfacción | Desviación | 1.5 |
| Medicamentos que decidió no tomar | ||
| Satisfacción | Desviación | 1.7 |
Recordemos que los estadísticos los podemos ir moviendo a nuestra necesidad para que se organicen de una forma u otra…
Dentro de columnas …
data %>%
tab_cells(P3) %>%
tab_cols(total(), mdset(P21A01 %to% P21A03)) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot(stat_position = "inside_columns")| #Total | Medicamentos que recetan por adelantado (para que no falten) | Envases que han quedado sin usar porque cambiaron el tratamiento | Medicamentos que decidió no tomar | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Media | Desviación | Media | Desviación | Media | Desviación | Media | Desviación | ||||
| Satisfacción | 7.3 | 7.2 | 7.2 | 6.4 | 6.9 | 1.5 | 6.7 | 1.7 | |||
Dentro de filas …
data %>%
tab_cells(P3) %>%
tab_cols(total(), mdset(P21A01 %to% P21A03)) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot(stat_position = "inside_rows")| #Total | Medicamentos que recetan por adelantado (para que no falten) | Envases que han quedado sin usar porque cambiaron el tratamiento | Medicamentos que decidió no tomar | |
|---|---|---|---|---|
| Satisfacción | ||||
| Media | 7.3 | 7.2 | 6.9 | 6.7 |
| Desviación | 7.2 | 6.4 | 1.5 | 1.7 |
Fuera de columnas …
data %>%
tab_cells(P3) %>%
tab_cols(total(), mdset(P21A01 %to% P21A03)) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot(stat_position = "outside_columns")| #Total | Medicamentos que recetan por adelantado (para que no falten) | Envases que han quedado sin usar porque cambiaron el tratamiento | Medicamentos que decidió no tomar | #Total | Medicamentos que recetan por adelantado (para que no falten) | Envases que han quedado sin usar porque cambiaron el tratamiento | Medicamentos que decidió no tomar | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Media | Media | Media | Media | Desviación | Desviación | Desviación | Desviación | ||||||||
| Satisfacción | 7.3 | 7.2 | 6.9 | 6.7 | 7.2 | 6.4 | 1.5 | 1.7 |
Fuera de filas …
data %>%
tab_cells(P3) %>%
tab_cols(total(), mdset(P21A01 %to% P21A03)) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot(stat_position = "outside_rows")| #Total | Medicamentos que recetan por adelantado (para que no falten) | Envases que han quedado sin usar porque cambiaron el tratamiento | Medicamentos que decidió no tomar | |
|---|---|---|---|---|
| Satisfacción | ||||
| Media | 7.3 | 7.2 | 6.9 | 6.7 |
| Desviación | 7.2 | 6.4 | 1.5 | 1.7 |
Repitamos ahora estas cuatro últimas tablas, pero en lugar de con una variable que genera grupos y de ellos se calcula la medida estadística, vamos a hacerlo con un cruce de categorías (un campo en columnas y otro en filas) y que en esos cruces, se calcule la medida estadística. Por ejemplo esta tabla me permitiría saber la media de P3 en los hombres de 18 a 25 años.
data %>%
tab_cells(P3) %>%
tab_cols(total(), mdset(P21A01 %to% P21A03)) %>%
tab_rows(P33) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot()| #Total | Medicamentos que recetan por adelantado (para que no falten) | Envases que han quedado sin usar porque cambiaron el tratamiento | Medicamentos que decidió no tomar | |||
|---|---|---|---|---|---|---|
| Estado civil de la persona entrevistada | ||||||
| Casado/a | Satisfacción | Media | 7.3 | 6.7 | 6.7 | 7.0 |
| Soltero/a | Satisfacción | Media | 7.2 | 8.2 | 6.8 | 6.4 |
| Viudo/a | Satisfacción | Media | 7.9 | 7.3 | 7.8 | 5.0 |
| Separado/a | Satisfacción | Media | 6.7 | 7.8 | 5.3 | 5.0 |
| Divorciado/a | Satisfacción | Media | 7.5 | 6.4 | 7.1 | 8.7 |
| N.C. | Satisfacción | Media | 18.2 | |||
| Casado/a | Satisfacción | Desviación | 6.7 | 2.0 | 1.5 | 1.3 |
| Soltero/a | Satisfacción | Desviación | 7.4 | 11.4 | 1.4 | 2.0 |
| Viudo/a | Satisfacción | Desviación | 6.9 | 1.7 | 2.0 | |
| Separado/a | Satisfacción | Desviación | 2.1 | 0.8 | 0.6 | |
| Divorciado/a | Satisfacción | Desviación | 9.5 | 2.1 | 1.2 | 2.3 |
| N.C. | Satisfacción | Desviación | 32.3 | |||
y juguemos con la posición del cálculo estadística que ahora sí arrojará cuatro configuraciones diferentes. La primera con los estadísticos dentro de las filas es idéntica a la anterior (por defecto).
data %>%
tab_cells(P3) %>%
tab_cols(total(), mdset(P21A01 %to% P21A03)) %>%
tab_rows(P33) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot(stat_position = "outside_rows") # por defecto, sin lo ponemos muestra esta opción| #Total | Medicamentos que recetan por adelantado (para que no falten) | Envases que han quedado sin usar porque cambiaron el tratamiento | Medicamentos que decidió no tomar | |||
|---|---|---|---|---|---|---|
| Estado civil de la persona entrevistada | ||||||
| Casado/a | Satisfacción | Media | 7.3 | 6.7 | 6.7 | 7.0 |
| Soltero/a | Satisfacción | Media | 7.2 | 8.2 | 6.8 | 6.4 |
| Viudo/a | Satisfacción | Media | 7.9 | 7.3 | 7.8 | 5.0 |
| Separado/a | Satisfacción | Media | 6.7 | 7.8 | 5.3 | 5.0 |
| Divorciado/a | Satisfacción | Media | 7.5 | 6.4 | 7.1 | 8.7 |
| N.C. | Satisfacción | Media | 18.2 | |||
| Casado/a | Satisfacción | Desviación | 6.7 | 2.0 | 1.5 | 1.3 |
| Soltero/a | Satisfacción | Desviación | 7.4 | 11.4 | 1.4 | 2.0 |
| Viudo/a | Satisfacción | Desviación | 6.9 | 1.7 | 2.0 | |
| Separado/a | Satisfacción | Desviación | 2.1 | 0.8 | 0.6 | |
| Divorciado/a | Satisfacción | Desviación | 9.5 | 2.1 | 1.2 | 2.3 |
| N.C. | Satisfacción | Desviación | 32.3 | |||
Los estadísticos fuera de las filas …
data %>%
tab_cells(P3) %>%
tab_cols(total(), mdset(P21A01 %to% P21A03)) %>%
tab_rows(P33) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot(stat_position = "inside_rows")| #Total | Medicamentos que recetan por adelantado (para que no falten) | Envases que han quedado sin usar porque cambiaron el tratamiento | Medicamentos que decidió no tomar | |||
|---|---|---|---|---|---|---|
| Estado civil de la persona entrevistada | ||||||
| Casado/a | Satisfacción | Media | 7.3 | 6.7 | 6.7 | 7.0 |
| Desviación | 6.7 | 2.0 | 1.5 | 1.3 | ||
| Soltero/a | Satisfacción | Media | 7.2 | 8.2 | 6.8 | 6.4 |
| Desviación | 7.4 | 11.4 | 1.4 | 2.0 | ||
| Viudo/a | Satisfacción | Media | 7.9 | 7.3 | 7.8 | 5.0 |
| Desviación | 6.9 | 1.7 | 2.0 | |||
| Separado/a | Satisfacción | Media | 6.7 | 7.8 | 5.3 | 5.0 |
| Desviación | 2.1 | 0.8 | 0.6 | |||
| Divorciado/a | Satisfacción | Media | 7.5 | 6.4 | 7.1 | 8.7 |
| Desviación | 9.5 | 2.1 | 1.2 | 2.3 | ||
| N.C. | Satisfacción | Media | 18.2 | |||
| Desviación | 32.3 | |||||
Los estadísticos dentro de las columnas …
data %>%
tab_cells(P3) %>%
tab_cols(total(), mdset(P21A01 %to% P21A03)) %>%
tab_rows(P33) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot(stat_position = "inside_columns")| #Total | Medicamentos que recetan por adelantado (para que no falten) | Envases que han quedado sin usar porque cambiaron el tratamiento | Medicamentos que decidió no tomar | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Media | Desviación | Media | Desviación | Media | Desviación | Media | Desviación | ||||||
| Estado civil de la persona entrevistada | |||||||||||||
| Casado/a | Satisfacción | 7.3 | 6.7 | 6.7 | 2.0 | 6.7 | 1.5 | 7.0 | 1.3 | ||||
| Soltero/a | Satisfacción | 7.2 | 7.4 | 8.2 | 11.4 | 6.8 | 1.4 | 6.4 | 2.0 | ||||
| Viudo/a | Satisfacción | 7.9 | 6.9 | 7.3 | 1.7 | 7.8 | 2.0 | 5.0 | |||||
| Separado/a | Satisfacción | 6.7 | 2.1 | 7.8 | 0.8 | 5.3 | 0.6 | 5.0 | |||||
| Divorciado/a | Satisfacción | 7.5 | 9.5 | 6.4 | 2.1 | 7.1 | 1.2 | 8.7 | 2.3 | ||||
| N.C. | Satisfacción | 18.2 | 32.3 | ||||||||||
Los estadísticos fuera de las columnas …
data %>%
tab_cells(P3) %>%
tab_cols(total(), mdset(P21A01 %to% P21A03)) %>%
tab_rows(P33) %>%
tab_stat_mean(label = "Media") %>%
tab_stat_sd(label = "Desviación") %>%
tab_pivot(stat_position = "outside_columns")| #Total | Medicamentos que recetan por adelantado (para que no falten) | Envases que han quedado sin usar porque cambiaron el tratamiento | Medicamentos que decidió no tomar | #Total | Medicamentos que recetan por adelantado (para que no falten) | Envases que han quedado sin usar porque cambiaron el tratamiento | Medicamentos que decidió no tomar | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Media | Media | Media | Media | Desviación | Desviación | Desviación | Desviación | ||||||||||
| Estado civil de la persona entrevistada | |||||||||||||||||
| Casado/a | Satisfacción | 7.3 | 6.7 | 6.7 | 7.0 | 6.7 | 2.0 | 1.5 | 1.3 | ||||||||
| Soltero/a | Satisfacción | 7.2 | 8.2 | 6.8 | 6.4 | 7.4 | 11.4 | 1.4 | 2.0 | ||||||||
| Viudo/a | Satisfacción | 7.9 | 7.3 | 7.8 | 5.0 | 6.9 | 1.7 | 2.0 | |||||||||
| Separado/a | Satisfacción | 6.7 | 7.8 | 5.3 | 5.0 | 2.1 | 0.8 | 0.6 | |||||||||
| Divorciado/a | Satisfacción | 7.5 | 6.4 | 7.1 | 8.7 | 9.5 | 2.1 | 1.2 | 2.3 | ||||||||
| N.C. | Satisfacción | 18.2 | 32.3 | ||||||||||||||
Bien, como has podido observar, el resultado no difiere cuando es múltiple a cuando es simple. Igual que hemos calculado la media y la desviación lo podemos hacer con otros estadísticos:
- media
- desviación
- máximo
- mínimo
- mediana
- suma
- error estándar
- un caso especial que calcula media, desviación y nº de casos
- algunos otros que iremos mostrando para temas muy específicos.
2.6 Conclusión a la creación de tablas
Creo que esta primera muestra de cómo procesar tablas de una única variable o cruzadas, es más que suficiente para colmar las expectativas más exigentes. Para aquellos que conozcan un poco más el funcionamiento de R, indicar que cada una de estas tablas, se puede almacenar como objeto sobre el que se puede trabajar. Este objeto es del tipo etable pero en el fondo es un objeto de tipo dataframe que por tanto puedes ser trabajado con comandos R estándar.
Es de esta posibilidad de ser un dataframe de donde deriva su capacidad de integración con otros paquetes como por ejemplo highcharter Kunst (2020) que será uno de nuestros paquetes de referencia para gráficos. Para una presentación completa, véase la sesión R2 de visualizacion gráfica para una presentación de gráficos a partir de un dataframe o de tablas marginales / cruzadas.
2.7 Pruebas inferenciales
Cuando trabajamos con tablas de contingencia es muy frecuente que sintamos la necesidad de tener que inferir acerca de la dependencia de las categorías analizadas o de las diferencias entre los grupos analizados. Siempre que nuestras variables cumplan con los requisitos que para ellas cada prueba establece (normalidad, homoscedasticidad, linealidad y en algunos casos independencia), podremos aplicar las pruebas inferenciales típicas con tablas de contingencia en la investigación básica:
- Chi2 en su variantes de tabla y celda;
- Pruebas z de contraste proporciones;
- Prueba t de contraste de medias.
Para todas ellas expss nos da la oportunidad de hacer los cálculos desde el propio script de realización de la tabla y/o desde una instrucción posterior a la realización de la tabla. Pasemos por ello a explicar, no tanto el cometido de estas pruebas, sino el como llevarlas adelante.
2.7.1 Prueba de dependencia
El contraste Chi2 de Pearson es una prueba estadística no paramétrica, que compara las frecuencias realmente obtenidas con las frecuencias esperadas que son las que corresponderían a cada celda o casilla de la tabla si su valor se ajustase a cualquier norma teórica previamente adoptada; en nuestro caso, una distribución proporcional de frecuencias normales. En definitiva, “se está calculando un índice acerca de la distancia entre lo real y lo esperado” Manzano Arrondo (1995).
El valor numérico de esta prueba se obtiene como:
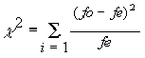
- fo, serán las frecuencias observadas en el experimento o muestra
- fe, serán las frecuencias esperadas teóricamente
Las frecuencias esperadas se calculan con …
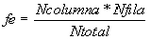
- fo, serán las frecuencias observadas en el experimento o muestra
- fe, serán las frecuencias esperadas teóricamente
- N, es el número de efectivos muestrales
Esta prueba se suele utilizar (entre muchas otras posibilidades) para contrastar la hipótesis nula que los resultados obtenidos de una muestra no son significativos con relación a la población total, o bien como prueba de dependencia para comprobar la existencia o no de asociación entre las variables. En este caso, la prueba indica la existencia de asociación pero no la cuantifica Manzano Arrondo (1995).
2.7.1.1 De una tabla
La prueba Chi2 puede hacerse a nivel de tabla, lo que muestra la relación de dependencia entre las categorías. Hagamos una primera aproximación con dos tablas de contingencia muy sencillas, pero que nos mostrarán como se indica que la relación de dependencia existe o no existe. La función tab_last_sig_cases realiza la prueba base de R denominada chisq.test.
Nótese el uso de ‘|’=unvr() para utilizar la variable sin que se publiquen los texto extra de la misma.
data %>%
tab_cols(total(), '|'=unvr(P31)) %>%
tab_cells('|'=unvr(P2)) %>%
tab_stat_cases() %>%
tab_last_sig_cases() %>%
tab_pivot()| #Total | Hombre | Mujer | |
|---|---|---|---|
| En general, el sistema sanitario funciona bastante bien | 538.0 | 277.0 | 261.0 |
| El sistema sanitario funciona bien, aunque son necesarios al | 1247.0 | 620.0 | 627.0 |
| El sistema sanitario necesita cambios fundamentales, aunque | 637.0 | 288.0 | 349.0 |
| Nuestro sistema sanitario está tan mal que necesitaríamos re | 120.0 | 61.0 | 59.0 |
| N.S. | 9.0 | 6.0 | 3.0 |
| N.C. | 6.0 | 4.0 | 2.0 |
| #Chi-squared p-value | (warn.) | ||
| #Total cases | 2557.0 | 1256.0 | 1301.0 |
data %>%
tab_cols(total(), '|'=unvr(P31)) %>%
tab_cells('|'=unvr(P33)) %>%
tab_stat_cases() %>%
tab_last_sig_cases() %>%
tab_pivot()| #Total | Hombre | Mujer | |
|---|---|---|---|
| Casado/a | 1388.0 | 677.0 | 711.0 |
| Soltero/a | 817.0 | 455.0 | 362.0 |
| Viudo/a | 190.0 | 41.0 | 149.0 |
| Separado/a | 57.0 | 24.0 | 33.0 |
| Divorciado/a | 97.0 | 55.0 | 42.0 |
| N.C. | 8.0 | 4.0 | 4.0 |
| #Chi-squared p-value | <0.05 (warn.) | ||
| #Total cases | 2557.0 | 1256.0 | 1301.0 |
En la primera tabla se muestra la relación entre la variable P31 (sexo) y la P2 (valoración del sistema sanitario). Nótese que en la tabla se ha usado una línea tras el cálculo de los casos con la función tab_last_sig_cases() que indica que se debe realizar la prueba Chi2 a la relación. Esta línea provoca que en la tabla surja una nueva fila sobre el #Total con el texto #Chi-squared p-value que indica que se realiza la prueba al 5% (0,05). Si el resultado es el rechazo de la hipótesis nula de independencia se muestra un #Chi-squared p-value <0.05 (warn.), pero si no se puede rechazar la hipótesis nula de independencia sale sólo #Chi-squared p-value <0.05 En la tabla no se publica el resultado de la prueba, pero podemos hacerlo siguiendo el formato estándar.
table(data$P2, data$P31)
Hombre Mujer
En general, el sistema sanitario funciona bastante bien 277 261
El sistema sanitario funciona bien, aunque son necesarios al 620 627
El sistema sanitario necesita cambios fundamentales, aunque 288 349
Nuestro sistema sanitario está tan mal que necesitaríamos re 61 59
N.S. 6 3
N.C. 4 2chisq.test(table(data$P2, data$P31))
Pearson's Chi-squared test
data: table(data$P2, data$P31)
X-squared = 7.2669, df = 5, p-value = 0.2015table(data$P33, data$P31)
Hombre Mujer
Casado/a 677 711
Soltero/a 455 362
Viudo/a 41 149
Separado/a 24 33
Divorciado/a 55 42
N.C. 4 4chisq.test(table(data$P33, data$P31))
Pearson's Chi-squared test
data: table(data$P33, data$P31)
X-squared = 75.203, df = 5, p-value = 8.437e-15Donde se puede observar que para la primera relación, no se puede rechazar la hipótesis de independencia pues el valor de significación es p-value > 0,05 (0.2015); para la segunda relación, sí podemos rechazar la hipótesis nula de independencia, puesto que p-value < 0,05 (por tanto, existe dependencia).
2.7.1.2 De una celda de una tabla
Particularmente de interés es la prueba Chi2 de celda. A diferencia de la anterior, en este caso se realiza la prueba para cada celda de la tabla en particular. La lógica de la misma sería comparar un valor de la tabla (una celda), con el resto de su fila, el resto de su columna, y el resto de la muestra. De este forma, indicamos que valores son significativos en la tabla, aquellos que cabría contemplar con un interés especial.
Para obtener la tabla y la subsiguiente prueba se utilizará una nueva función denominada tab_last_sig_cell_chisq() sobre la misma estructura ya conocida de tabla. Nótese que en este caso, para la prueba se requiere utilizar los porcentajes en lugar de los casos, para que el cálculo sea el oportuno. Chi2 es una prueba muy sensible al tamaño de la muestra.
data %>%
tab_cols(total(), '|'=unvr(P31)) %>%
tab_cells('|'=unvr(P2)) %>%
tab_stat_cpct() %>%
tab_last_sig_cell_chisq() %>%
tab_pivot()| #Total | Hombre | Mujer | |
|---|---|---|---|
| En general, el sistema sanitario funciona bastante bien | 21.0 | 22.1 | 20.1 |
| El sistema sanitario funciona bien, aunque son necesarios al | 48.8 | 49.4 | 48.2 |
| El sistema sanitario necesita cambios fundamentales, aunque | 24.9 | 22.9 < | 26.8 > |
| Nuestro sistema sanitario está tan mal que necesitaríamos re | 4.7 | 4.9 | 4.5 |
| N.S. | 0.4 | 0.5 | 0.2 |
| N.C. | 0.2 | 0.3 | 0.2 |
| #Total cases | 2557 | 1256 | 1301 |
data %>%
tab_cols(total(), '|'=unvr(P31)) %>%
tab_cells('|'=unvr(P33)) %>%
tab_stat_cpct() %>%
tab_last_sig_cell_chisq() %>%
tab_pivot()| #Total | Hombre | Mujer | |
|---|---|---|---|
| Casado/a | 54.3 | 53.9 | 54.7 |
| Soltero/a | 32.0 | 36.2 > | 27.8 < |
| Viudo/a | 7.4 | 3.3 < | 11.5 > |
| Separado/a | 2.2 | 1.9 | 2.5 |
| Divorciado/a | 3.8 | 4.4 | 3.2 |
| N.C. | 0.3 | 0.3 | 0.3 |
| #Total cases | 2557 | 1256 | 1301 |
La salida es muy clara. Con los símbolos mayor y menor, se marcan aquellas celdas que son significativamente mayores (>) o menores (<) que lo esperado y por tanto son las que direccionan las relaciones de dependencia que en la tabla se producen.
2.7.2 Pruebas de diferencias
Un conjunto diferentes de pruebas son aquellas cuya hipótesis de partida se basa en determinar si existen diferencias entre los porcentajes (prueba z) o las medias (prueba t) de dos grupos independientes en la muestra extraídos de la misma población. Desarrollamos ambas pruebas en las líneas siguientes.
2.7.2.1 Porcentajes (prueba z)
Asumiendo las hipótesis necesarias para poder trabajar con estadística paramétrica (normalidad, homoscedasticidad, linealidad y en algunos casos independencia), la función tab_last_sig_cpct realiza z-test entre columnas de porcentajes derivadas de la aplicación de tab_stat_cpct. Los resultados son calculados con la misma fórmula que con la función base de R prop.test y sin la corrección de continuidad.
Obsérvese la diferencia de concepto; mientras que la prueba Chi2 de celda realiza la prueba comparando con el marginal total, la prueba z realiza esa comparación entre los grupos formados por las columnas, a los que se suele llamar perfiles. De esta forma considera la independencia de los grupos muestrales entre sí.
Para utilizar esta funcionalidad el script sería el siguiente:
data %>%
tab_cols(total(), 'SEXO'=unvr(P31)) %>%
tab_cells('|'=unvr(P2)) %>%
tab_stat_cpct() %>%
tab_last_sig_cpct() %>%
tab_pivot()| #Total | SEXO | ||||
|---|---|---|---|---|---|
| Hombre | Mujer | ||||
| A | B | ||||
| En general, el sistema sanitario funciona bastante bien | 21.0 | 22.1 | 20.1 | ||
| El sistema sanitario funciona bien, aunque son necesarios al | 48.8 | 49.4 | 48.2 | ||
| El sistema sanitario necesita cambios fundamentales, aunque | 24.9 | 22.9 | 26.8 A | ||
| Nuestro sistema sanitario está tan mal que necesitaríamos re | 4.7 | 4.9 | 4.5 | ||
| N.S. | 0.4 | 0.5 | 0.2 | ||
| N.C. | 0.2 | 0.3 | 0.2 | ||
| #Total cases | 2557 | 1256 | 1301 | ||
data %>%
tab_cols(total(), 'SEXO'=unvr(P31)) %>%
tab_cells('|'=unvr(P33)) %>%
tab_stat_cpct() %>%
tab_last_sig_cpct() %>%
tab_pivot()| #Total | SEXO | ||||
|---|---|---|---|---|---|
| Hombre | Mujer | ||||
| A | B | ||||
| Casado/a | 54.3 | 53.9 | 54.7 | ||
| Soltero/a | 32.0 | 36.2 B | 27.8 | ||
| Viudo/a | 7.4 | 3.3 | 11.5 A | ||
| Separado/a | 2.2 | 1.9 | 2.5 | ||
| Divorciado/a | 3.8 | 4.4 | 3.2 | ||
| N.C. | 0.3 | 0.3 | 0.3 | ||
| #Total cases | 2557 | 1256 | 1301 | ||
En nuestro caso, los resultados son muy semejantes a los vistos con Chi2 de celda, porque la variable elegida para las columnas es dicotómica, es decir, con sólo dos opciones de respuesta, exhaustivas y mutuamente excluyentes. No sería así si la variable de columnas presentara más de 2 perfiles.
La lectura de esta prueba es la siguiente. El porcentaje de casos en en el grupo B (mujeres) de la tabla 1, es significativamente más elevado que el de hombres, determinándose esta diferencia con una significación del 5%. En el caso de la tabla 2, el porcentaje de hombres solteros es significativamente diferente del porcentaje de mujeres solteras. Del mismo modo y a la inversa el porcentaje de mujeres viudas entrevistadas en la muestra es significativamente mayor que el de hombres.
Por tanto, creemos que queda claro el funcionamiento de la prueba. Se etiquetan las columnas y se muestra la letra de la columna con la que se presentan diferencias positivas junto al valor porcentual. La prueba se realiza para cada celda, pero siempre comparando con las celdas que tiene a su derecha o izquierda en la misma fila (no con el total).
2.7.2.2 Medias (prueba t)
Al igual que en el apartado anterior el objetivo es determinar si existen o no diferencias entre los grupos que se están testando, teniendo como hipótesis nula que las medias de los grupos son iguales. En nuestro ejemplo, hemos tomado la de auto clasificación ideológica (recodificando las posiciones de 1 a 10, izquierda a derecha respectivamente) creando grupos de izquierda, centro y derecha. Sobre esta tabla que calcula las medias, se aplica el estadístico tab_stat_mean_sd_n()que contiene todos los datos requeridos para el cálculo del valor t y se le indica que requerimos el test con tab_last_sig_means(). Se asume que los grupos son independientes, que existe normalidad y que las varianzas de los grupos son iguales.
data$P29BIS <- expss::recode(data$P29, 'Izquierda' = 1:4 ~1, 'Centro' = 5:6 ~2, 'Derecha' = 7:10 ~ 3, TRUE ~NA)
data %>%
tab_cols(total(), P29) %>%
tab_cells(P3) %>%
tab_mis_val(gt(10)) %>%
tab_stat_mean_sd_n() %>%
tab_last_sig_means() %>%
tab_pivot()| #Total | Escala de autoubicación ideológica (1-10) | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 Izquierda | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 Derecha | N.S. | N.C. | ||||||||||||||
| A | B | C | D | E | F | G | H | I | J | K | L | ||||||||||||||
| Satisfacción | |||||||||||||||||||||||||
| Mean | 6.8 | 6.0 | 6.4 | 6.7 A | 6.9 A B | 6.7 A | 7.0 A B | 7.0 A B | 7.0 A B | 7.9 A B C D E F G H K L | 7.5 A B C | 6.9 A | 6.8 A | ||||||||||||
| Std. dev. | 1.9 | 2.2 | 1.9 | 1.7 | 1.8 | 1.8 | 1.8 | 1.9 | 2.0 | 1.8 | 2.3 | 2.0 | 1.9 | ||||||||||||
| Unw. valid N | 2542.0 | 85.0 | 97.0 | 301.0 | 287.0 | 541.0 | 209.0 | 153.0 | 121.0 | 40.0 | 34.0 | 327.0 | 347.0 | ||||||||||||
Se puede observar que la salida es igual a la de la prueba Z. Se rotulan las columnas con las letras A, B … y las que sean necesarias, y posteriormente se muestra (por defecto) la letra de la columna con la que la media de la columna en la que se ubica la media presenta diferencias positivas (es mayor). Podemos por tanto observar, que en la población de la que se ha extraído la muestra, se puede afirmar que la media de satisfacción con el funcionamiento del sistema sanitario español es más alta en los individuos cuya auto clasificación ideológica es del grupo de derecha (C), que en la izquierda (A) y en el centro (B). No entramos a valorar si la distribución de grupos es la correcta o no, en cuanto al significado general. Se ha hecho una distribución acorde al significado de los números en sí mismos.
Existen ocasiones en las que esta prueba, se requiere publicar para un conjunto de ítemes que forman parte de una misma batería. En estos casos, no es tan interesante publicar las desviaciones y las bases, por lo que podemos formular de esta forma el script.
data %>%
tab_cols(total(), P29BIS) %>%
tab_cells(P901) %>%
tab_mis_val(gt(10)) %>%
tab_stat_mean_sd_n() %>%
tab_last_sig_means(keep='means') %>%
tab_cells(P902) %>%
tab_mis_val(gt(10)) %>%
tab_stat_mean_sd_n() %>%
tab_last_sig_means(keep='means') %>%
tab_cells(P903) %>%
tab_mis_val(gt(10)) %>%
tab_stat_mean_sd_n() %>%
tab_last_sig_means(keep='means') %>%
tab_cells(P904) %>%
tab_mis_val(gt(10)) %>%
tab_stat_mean_sd_n() %>%
tab_last_sig_means(keep='means') %>%
tab_cells(P905) %>%
tab_mis_val(gt(10)) %>%
tab_stat_mean_sd_n() %>%
tab_last_sig_means(keep='means') %>%
tab_cells(P906) %>%
tab_mis_val(gt(10)) %>%
tab_stat_mean_sd_n() %>%
tab_last_sig_means(keep='means') %>%
tab_cells(P907) %>%
tab_mis_val(gt(10)) %>%
tab_stat_mean_sd_n() %>%
tab_last_sig_means(keep='means') %>%
tab_pivot()| #Total | P29BIS | ||||||
|---|---|---|---|---|---|---|---|
| Izquierda | Centro | Derecha | |||||
| A | B | C | |||||
| Los cuidados y la atención recibida del personal médico | |||||||
| Mean | 7.7 | 7.7 | 7.8 | 7.9 | |||
| Los cuidados y la atención recibida del personal de enfermería | |||||||
| Mean | 7.8 | 7.8 | 7.7 | 7.9 | |||
| La confianza y seguridad que transmite el personal médico | |||||||
| Mean | 7.8 | 7.7 | 7.8 | 8.0 A | |||
| La confianza y seguridad que transmite el personal de enfermería | |||||||
| Mean | 7.8 | 7.7 | 7.7 | 8.0 A B | |||
| El tiempo dedicado por el médico o la médica a cada enfermo o enferma | |||||||
| Mean | 7.1 | 6.9 | 7.0 | 7.2 | |||
| El conocimiento del historial y seguimiento de los problemas de salud de cada usuario o usuaria | |||||||
| Mean | 7.5 | 7.4 | 7.4 | 7.7 A B | |||
| La información recibida sobre su problema de salud | |||||||
| Mean | 7.5 | 7.4 | 7.5 | 7.8 A B | |||
Se puede observar que la instrucción keep='means' lo que ha conseguido es eliminar la publicación de la desviación y la media del cuadro presentado. De este modo el resultado es más compacto y da una visión general de la batería de ítemes
2.7.3 Parámetros posibles en las pruebas de significación
De manera conjunta exponemos aquí diferentes parámetros que modifican el comportamiento por defecto de las cuatro pruebas anteriormente vistas. Algunos son de uso en todas ellas y otros específicos de alguna de las pruebas.
sig_level, numérico; nivel de significación, por defecto es igual a 0.05.min_base, numérico; el test de significación se realizará si ambas columnas tienes bases mayores o iguales al valor determinado que por defecto es 2.delta_cpct, numérico; delta mínimo entre el porcentaje para el que marcamos diferencias significativas (en puntos porcentuales); de forma predeterminada, es igual a cero. Tenga en cuenta que, por ejemplo, para una diferencia mínima de 5 por ciento de puntos, delta_cpct debe ser igual a 5, no 0.05.delta_means, numérico; delta mínimo entre medias para las que marcamos diferencias significativas: por defecto es igual a cero.correct, lógico (TRUE o FALSE), indica si aplicar corrección de continuidad al calcular el estadístico Chi2 de prueba para tablas de 2 por 2. Solo parasignificance_casesysignificance_cell_chisq. Para más detalles ver chisq.test. TRUE por defecto.compare_typetipo de comparación por columnas. Por defecto, es subtabla (variable por variable). otras posibilidades son"first_column","adjusted_first_column"y"previous_column"; podemos realizar varios test simultáneamente.bonferronilógico; FALSE por defecto; uso del ajuste de Bonferroni por cada fila.subtable_marks, carácter; una de las siguientes opciones:"greater","both"or"less"; por defecto se marcan sólo valores cuya significación sea mayor ("greater") que alguna otra columna. Parasignificance_cell_chisqpor defecto es"both". podemos modificar este comportamiento usando las otras alternativas.inequality_signlogical. FALSE if subtable_marks is “less” or “greater”. Should we show > or < before significance marks of subtable comparisons.sig_labelscharacter vector labels for marking differences between columns of subtable.sig_labels_previous_columna character vector with two elements. Labels for marking a difference with the previous column. First mark means ‘lower’ (by default it is v) and the second means greater (^).sig_labels_first_columna character vector with two elements. Labels for marking a difference with the first column of the table. First mark means ‘lower’ (by default it is -) and the second means ‘greater’ (+).sig_labels_chisqa character vector with two labels for marking a difference with row margin of the table. First mark means ‘lower’ (by default it is <) and the second means ‘greater’ (>). Only for significance_cell_chisq.keep, carácter. Una o más de las siguientes"percent","cases","means","bases","sd"o"none". Este argumento determina qué estadísticos permanecerán en la tabla después del marcado de significación.row_margin, carácter. Uno de los valores"auto"(predeterminado),"sum_row"o"first_column". Si es"auto", tratamos de encontrar la columna total en la subtabla portotal_column_marker. Si la búsqueda falla, usamos la suma de cada fila como total de filas. Con la opción"sum_row"siempre sumamos cada fila para obtener margen. Tenga en cuenta que en este caso el resultado de las variables de respuesta múltiple en la cabecera puede ser incorrecta. Con la opción"first_column"usamos la tabla primera columna como margen de fila para todas las subtablas. En este caso, el resultado de las subtablas con bases incompletas puede ser incorrecto. Solo parasignificance_cell_chisq.total_marker, carácter. Total de fila marcado en la tabla." # "por defecto.total_row, entero/carácter. En el caso de varios totales por subtabla, es un número o nombre de fila total para el cálculo de significación.digits, un número entero que indica cuántos dígitos después del separador decimal se mostrarán en la tabla final.na_as_zero, lógico; FALSE por defecto. ¿Deberíamos tratar a NA como cero casos?var_equal, lógico; variable que indica si se deben tratar las dos varianzas como iguales. Para más detalles ver t.test.mode, carácter;"replace" (default)o"append". En el primer caso, el resultado anterior en la secuencia del cálculo de la tabla se reemplazará con el resultado de la prueba de significación. En el segundo caso, el resultado de la prueba de significación se agregará a la secuencia del cálculo de la tabla.label, carácter; etiqueta para la estadística en tab_*. Ignorado si el modo es igual areplace.total_column_marker, carácter; marca para la columna de totales en las subtablas. “#” por defecto.xtable (class etable): result of cro_cpct with proportions and bases for significance_cpct, result of cro_mean_sd_n with means, standard deviations and valid N for significance_means, and result of cro_cases with counts and bases for significance_cases.cases_matrix, matriz numérica con recuentos de tamaño filas*columnas.row_base, vector de números con las bases de fila.col_base, vector de números con las bases de columna.total_base, número con la base total.
2.7.3.1 Algunos ejemplos de uso de los parámetros
Cambio del nivel de significación de la prueba y eliminación de las filas con las frecuencias, entre otros…
data %>%
tab_cols(total(), '|'=unvr(P31)) %>%
tab_cells('|'=unvr(P33)) %>%
tab_stat_cases() %>%
tab_last_sig_cases(sig_level = 0.01, correct = TRUE, keep='bases', mode='replace', label='***') %>%
tab_pivot()| #Total | Hombre | Mujer | |
|---|---|---|---|
| #Chi-squared p-value | <0.01 (warn.) | ||
| #Total cases | 2557.0 | 1256.0 | 1301.0 |
2.7.4 Conclusión
Hasta aquí llegamos. Hemos presentado de forma muy breve y simplificada como podemos aprovechar toda la potencia de expss en nuestros script. Lo importante es practicar y practicar. No dejes de acudir a las viñetas de ayuda de Gregory Demin acerca de como usar el paquete y como generar nuevas tablas. Nosotros tan sólo hemos sentado las bases. Combinando las tablas con lenguaje R se puede llegar a conseguir casi todo.
2.8 Visualización gráfica
2.8.1 highcharteR, introducción
El paquete highcharter es un contenedor para la biblioteca Highcharts que incluye funciones de acceso directo para trazar objetos gráficos de R. Es una biblioteca de gráficos que ofrece numerosos tipos de gráficos con una sintaxis de configuración muy simple y repetitiva. Suponemos que ya estás acostumbrado a trabajar con R, por lo que no te resultará complicado seguir los pasos aquí indicados.
Este documento fundamentalmente se ha dedicado a trabajar con tablas cruzadas (o mejor con los dataframe creados con esas tablas), ese elemento que tanta productividad produce y que tan claras deja las visualizaciones; sin embargo la mayoría de librerías de gráficos trabajan con dataframe, por lo que deberemos hacer una simplificación de la tabla para trabajar con ella de forma adecuada. No sería necesario, pero como digo te ayudará a ver con otros ojos la simplicidad de highcharter. Comenzaremos trabajando con la base de la librería y en el desarrollo del capítulo indicaremos como trabajar con tablas cruzadas.
Debemos saber que highcharteRnos permite utilizar dos tipos diferentes de funciones que a continuación explicamos, aunque nos centramos en la primera de ellas. La segunda es una forma de acortar la primera.
highchart()hchart()
2.8.1.1 highchart()
Esta función crea un gráfico highchart usando un widget. El widget creado se puede representar en páginas HTML generadas a partir de rmarkdown y con características de interactividad. Si estás familiarizado con el paquete ggplot2 (Wickham (2016)), es una función similar a ggplot() del paquete donde se define un objeto ggplot base sobre el cual se pueden agregar más capas geométricas. De manera similar, una vez que se define la función highchart(), se pueden agregar más elementos highchart encima de ella, como si fueran capas superpuestas.
2.8.1.2 hchart()
Por otro lado, hchart () es una función genérica para dibujar diferentes gráficos sobre la marcha. El gráfico resultante es un objeto highchart, por lo que puede seguir modificando con la API implícita. Si estás familiarizado con ggplot2, esta función es similar a qplot(). Comencemos nuestro viaje de visualización interactiva con los diseño más sencillos.
2.8.2 Mi primer gráfico
Para trabajar con los gráficos, utilizaremos la siguiente tabla de datos, muy sencilla, propuesta por el autor del paquete, que además contiene los nombres de campo estandarizados que nos van a ayudar a de forma muy sencilla a generar nuestras visualizaciones.
Lo primero que debemos saber, es que hay unos nombres de campo (por defecto) en el dataframe cuya presencia facilita enormemente el trabajo con los gráficos. Mira esta tabla de datos. En esta tabla son muy importantes los nombres de los campos, porque su existencia hace que sin apenas código, el gráfico ya visualiza de acuerdo a nuestra necesidad.
| x | y | z | low | high | value | name | color | from | to | weight |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.6 | -34.0 | -6.0 | 9.2 | 1 | lemon | #d35400 | lemon | olive | 1 |
| 1 | 11.0 | -23.0 | 6.7 | 15.3 | 10 | nut | #2980b9 | lemon | guava | 1 |
| 2 | 20.4 | 6.8 | 2.8 | 38.0 | 19 | olive | #2ecc71 | lemon | fig | 1 |
| 3 | 22.1 | 32.3 | 19.4 | 24.8 | 21 | guava | #f1c40f | nut | olive | 1 |
| 4 | 15.4 | 27.7 | 12.1 | 18.7 | 14 | fig | #2c3e50 | olive | pear | 2 |
| 5 | 7.4 | 3.2 | -11.8 | 26.6 | 6 | pear | #7f8c8d | guava | pear | 2 |
A saber …
x, que contiene la secuencia de datosy, que contiene el dato que habitualmente representaremos en el eje de las Y (ordenadas)z, dimensiona el valor de y cuando se quieren usar tres dimensiones de representación (por ejemplo cuando queremos que en un scatter la burbuja sea tan grande como una tercera variable)low, valor más bajo para la categoríahigh, valor más alto para la categoríavalue, valor de la categoríaname, que contiene lo nombres o textos de las categorías; suele ser lo que queremos que aparezca en el eje de las X (abscisas)color, código del color en hexadecimal que modificará el color por defecto de la serie (puede ser también el nombre del color)from, importante en gráficos especiales de tipo organización o donde hay una relación “desde”to, igual al anterior, importante en gráficos especiales de tipo organización o donde hay una relación “hasta”weight, utilizado en algunos gráficos a los que nos referiremos después.
2.8.3 Gráfico de barras
Un diagrama de barras (o columnas) muestra la relación entre una variable numérica (y) y una categórica (name). Cada entidad de la variable categórica se representa como una barra. El tamaño de la barra representa su valor numérico. A veces se describe como una forma aburrida de visualizar información. Sin embargo, probablemente sea la forma más eficaz de mostrar este tipo de datos.
Vamos a mostrar las dos formas de hacer este gráfico y entenderás la información que te aportábamos en la descripción anterior de las funciones posibles para hacer un gráfico.
require(highcharter) # solicitamos la carga de highcharter si no lo está ya
require(readr)
require(dplyr)
library(expss)
df <- suppressMessages(
read_csv("https://drive.google.com/uc?export=download&id=1OStFMmg5fzIpfTZnzX9Ql8sefN7se5SW", col_names=TRUE))
#df.csv, archivo con su ruta en el disco
df1 <- select(df, name, y, color) # seleccionamos las columnas name e y, por un motivo que más adelante explicamos
highchart() %>%
hc_chart(type = 'bar') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1)¿Por qué hemos seleccionado estos tres campos? Ya hemos hablado de la importancia del nombre de los campos en highcharter. El gráfico de barras que es un estándar, es transformado a un gráfico de barras low-high si se localizan estos nombres de campo, low y high en el dataframe de trabajo, y el dataframe original df los tenía. Por tanto si repetimos este gráfico, pero con el dataframe original con esos dos campos, veremos que variación se produce.
highchart() %>%
hc_chart(type = 'bar') %>%
hc_xAxis(categories = df$name) %>%
hc_add_series(df)La barra no se traza completa sino que se traza con origen en el valor más bajo (low), y con final en el valor más alto (high). Sin embargo si acercas el ratón a una barra, verás que el valor listado se corresponde con el campo y del dataframe.
Vamos a realizar unas pequeñas variaciones muy habituales en los gráficos.
2.8.3.1 Cambiar el nombre de la serie de datos
La primera modificación sería añadir el nombre de la serie al gráfico …
highchart() %>%
hc_chart(type = 'bar') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1,
name='Fruits')Podemos observar, como en ángulo inferior derecho de la ventana del gráfico aparece la palabra fruits que hemos escrito como nombre del conjunto de datos, que en realidad es una única serie.
2.8.3.2 Añadir créditos al gráfico
Añadir un pie de gráfico con créditos del creador del mismo.
highchart() %>%
hc_chart(type = 'bar') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1,
name='Fruits') %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com')Ver ángulo inferior derecho, justo debajo del nombre de la serie. Posibilidad de hacer clic y llegar hasta la URL indicada.
2.8.3.3 Añadir el valor del dato al elemento
En muchas ocasiones nos interesa activar que se visualice el valor del dato en el gráfico y no sólo en el tooltip del mismo. Para ello usaremos el modificador dataLabel.
highchart() %>%
hc_chart(type = 'bar') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1,
name='Fruits',
dataLabels=list(enabled=TRUE)) %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com')2.8.3.4 Guardar y exportar el gráfico
En ocasiones es necesario dar la oportunidad al usuario del gráfico de poder guardarlo como imagen o guardarlo como tabla de EXCEL o fichero de texto separado por ‘,’ (CSV).
highchart() %>%
hc_chart(type = 'bar') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1,
name='Fruits',
dataLabels=list(enabled=TRUE)) %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)2.8.3.5 API de Highcharts, toda la potencia de los gráficos
La pregunta que ahora nos deberíamos estar haciendo es… ¿como puedo yo saber que debo usar hc_credits(), o hc_exporting() o dataLabels(list=())?
Para eso tenemos lo que se llama la API de la librería de gráficos. Ahora entenderemos mejor el apartado de presentación cuando decíamos que highcharter es un wrapper de la librería Highcharts. Si visitamos el sitio web de la api de highcharts podemos ver que todas las opciones que se pueden usar en los gráficos están documentadas. Si a ello añadimos el sitio demo de esta marca podemos ver todo lo que se puede hacer. Te recomiendo la lectura del post de Danton Noriega acerca de como usar la API para saber construir nuestros gráficos en de highchart en R, en especial la parte en la que refiere a este punto que estamos hablando (Highcharts API and highcharter functions). Tras la lectura de ese documento te darás cuenta de que en tus manos de analista de datos, tienes un auténtico cañón de magníficas visualizaciones.
Pero vayamos poco a poco y continuemos con nuestros ejemplos de gráficos.
2.8.4 Gráfico de columna
Es un gráfico idéntico al anterior, pero con la barra vertical en lugar de horizontal. Mantenemos la última vista básica con los elementos añadidos de exportación, créditos y mostrado de valores de aquí en adelante.
highchart() %>%
hc_chart(type = 'column') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1,
name='Fruits',
dataLabels=list(enabled=TRUE)) %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)Obsérvese que en el gráfico lo único que hemos hecho ha sido modificar el tipo de gráfico de bara column. Añadamos ahora perspectiva al gráfico, incluyendo la lista de opciones de 3D.
highchart() %>%
hc_chart(type = 'column',
options3d = list(enabled = TRUE, beta = 45, alpha = 15)) %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1,
name='Fruits',
dataLabels=list(enabled=TRUE)) %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)2.8.4.1 Variación de columna a pirámide
Y si lo presentamos en forma de pirámide …
highchart() %>%
hc_chart(type = 'columnpyramid') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1,
name='Fruits',
showInLegend = FALSE,
dataLabels = list(enabled=TRUE)) %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)2.8.4.2 Variación de columna a lollipop
Y si lo presentamos en forma de lollipop, debemos variar al dataframe al completo, porque este gráfico muy parecido a la variación de rango, requiere del low-high.
highchart() %>%
hc_chart(type = 'dumbbell') %>%
hc_xAxis(categories = df$name) %>%
hc_add_series(df,
name='Fruits',
showInLegend = FALSE,
dataLabels = list(enabled=TRUE)) %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)highchart() %>%
hc_chart(type = 'dumbbell',
inverted=TRUE) %>%
hc_xAxis(categories = df$name) %>%
hc_add_series(df,
name='Fruits',
showInLegend = FALSE,
dataLabels = list(enabled=TRUE)) %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)2.8.4.3 Gráficos polares
Existe otra forma de visualizar el gráfico que nos va a gustar mucho, porque se ve en pocas ocasiones.
highchart() %>%
hc_chart(type = 'bar',
polar=TRUE) %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1,
name='Fruits',
dataLabels=list(enabled=TRUE)) %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)Nótese que se ha añadido el modificador polar=TRUE Una buena vista, espectacular pero poco efectiva. Desde el propio script, sin embargo se puede añadir una mínima opción que mejoraría esta salida.
highchart() %>%
hc_chart(type = 'bar',
polar=TRUE) %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1,
name='Fruits',
dataLabels=list(enabled=TRUE)) %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE) %>%
hc_pane(endAngle=270)Esta nueva función hc_pane() hace que el círculo termine en el ángulo 270 (de 360), de forma que las etiquetas se leen mejor. Pero no es una visualización fácil, visualmente atractiva, pero difícil de leer e intepretar.
2.8.5 Diagramas de secciones
2.8.5.1 Tarta o pie chart
Si hay algún gráfico tan o más famoso que el de barras o el de columnas, ese es el gráfico de tarta.
df$sliced <- c(0,1,0,0,1,0) #añadimos el campo sliced
highchart() %>%
hc_title(text = 'Fruits pie') %>%
hc_subtitle(text = 'My favourite fruits') %>%
hc_chart(type = 'pie',
polar = FALSE,
inverted = FALSE) %>%
hc_xAxis(categories = df$name) %>%
hc_add_series(df,
name = "Fruits",
showInLegend = TRUE)df <- select(df, -sliced) #eliminamos el campo slicedAdemás de haberle añadido un título y un subtítulo este gráfico presenta un nuevo elemento fundamental: el modificador showInLegend=TRUE que nos permite mostrar una leyenda con las diferentes frutas y sus colores. Además, en el script hemos comenzado por añadir un nuevo campo a la tabla df, denominado sliced que ya puedes ver su efecto, separa del centro una sección de la tarta. En este caso ha sucedido para la fruta en segundo lugar (nut) y para la que está en quinto lugar (fig).
2.8.5.2 Anillo o doughnut
Y si queremos convertir este gráfico en un anillo o doughnut utilizaremos el modificador innerSize='75%' en la función hc_add_series(). Este modificador traza un círculo desde el baricentro del diagrama hasta el porcentaje indicado dejando espacio central en blanco. El gráfico puede tomar diferente aspecto según ese porcentaje indicado.
highchart() %>%
hc_title(text = 'Fruits pie') %>%
hc_subtitle(text = 'My favourite fruits') %>%
hc_chart(type = 'pie',
polar = FALSE,
inverted = FALSE) %>%
hc_xAxis(categories = df$name) %>%
hc_add_series(df,name = "Fruits",
showInLegend = TRUE,
innerSize='75%' )o también, cambiando el radio inferior de vaciado …
highchart() %>%
hc_title(text = 'Fruits pie') %>%
hc_subtitle(text = 'My favourite fruits') %>%
hc_chart(type = 'pie',
polar = FALSE,
inverted = FALSE) %>%
hc_xAxis(categories = df$name) %>%
hc_add_series(df,name = "Fruits",
showInLegend = TRUE,
innerSize='33%')2.8.5.3 Funnel
Una variante para gráficos de un único campo es el funnel.
2.8.5.4 Pirámide
Una nueva variante para un gráfico de una sola variable. el tipo pyramid.
2.8.6 Gráfico de línea
Un nuevo pero tradicional modelo, el gráfico de línea. Vamos a aprovechar para no ser demasiado repetitivos para añadir una nueva serie de valores; recordemos la tabla de datos inicial.
| x | y | z | low | high | value | name | color | from | to | weight |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.6 | -34.0 | -6.0 | 9.2 | 1 | lemon | #d35400 | lemon | olive | 1 |
| 1 | 11.0 | -23.0 | 6.7 | 15.3 | 10 | nut | #2980b9 | lemon | guava | 1 |
| 2 | 20.4 | 6.8 | 2.8 | 38.0 | 19 | olive | #2ecc71 | lemon | fig | 1 |
| 3 | 22.1 | 32.3 | 19.4 | 24.8 | 21 | guava | #f1c40f | nut | olive | 1 |
| 4 | 15.4 | 27.7 | 12.1 | 18.7 | 14 | fig | #2c3e50 | olive | pear | 2 |
| 5 | 7.4 | 3.2 | -11.8 | 26.6 | 6 | pear | #7f8c8d | guava | pear | 2 |
Vamos a utilizar z, como si fuera una nueva serie de valores. Es decir como si quisiéramos representar en el diagrama dos conjuntos de valores. Primero lo mostramos como hasta ahora, con una sola serie…
df1 <- select(df, name, y, z, color) # seleccionamos las columnas name, y y z
highchart() %>%
hc_chart(type = 'line') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1, name='Fruits',
dataLabels=list(enabled=TRUE)) %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)Para ahora añadir la nueva serie. Nótese la variación en el modificador hc_add_series()donde ahora hay dos líneas, como si de dos capas se tratara.
highchart() %>%
hc_chart(type = 'line') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1,
name='Fruits - serie 1',
dataLabels=list(enabled=TRUE)) %>%
hc_add_series(df1$z,
name='Fruits - serie 2',
dataLabels=list(enabled=TRUE)) %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)Quisiera hacer notar que simplemente hemos añadido una nueva serie que se contiene en la columna denominada z de df1 (df1$z) y no hemos modificado la anterior serie que por defecto era el campo y. Creo que sería mucho más limpio y ordenado el escribir este mismo gráfico así.
highchart() %>%
hc_chart(type = 'line') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1$y, name='Fruits - serie 1', dataLabels=list(enabled=TRUE)) %>%
hc_add_series(df1$z, name='Fruits - serie 2', dataLabels=list(enabled=TRUE)) %>%
hc_credits(enabled=TRUE, text='InvestigaOnline.com', href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)De este modo, identificamos que es cada una de las series yy z, obteniendo idéntico resultado pero quedando más clara la sintaxis de cada una de las series introducidas.
2.8.6.0.1 Suavizado de la línea
En muchas ocasiones es interesante suavizar la línea. Para ello highcharts tiene un modificador del tipo de gráfico denominado spline.
highchart() %>%
hc_chart(type = 'spline') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1$y, name='Fruits - serie 1', dataLabels=list(enabled=TRUE)) %>%
hc_add_series(df1$z, name='Fruits - serie 2', dataLabels=list(enabled=TRUE)) %>%
hc_credits(enabled=TRUE, text='InvestigaOnline.com', href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)Nótese el suavizado de la curva.
Y ha llegado un momento de hacer algo no habitual, pero que sí puede darte ideas de futuro.
highchart() %>%
hc_chart(type = 'line') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1$y,
name='Fruits - serie 1',
dataLabels=list(enabled=TRUE)) %>%
hc_add_series(df1$z,
type='column',
name='Fruits - serie 2',
dataLabels=list(enabled=TRUE)) %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)Vaya sorpresón y qué sencillo, ¿verdad? Hemos combinado línea con columna (no todas las combinaciones son posibles). Además como z tenía valores negativos, las barras negativas se muestran muy claramente. ¿Y si polarizamos este gráfico?
highchart() %>%
hc_chart(type = 'line', polar=TRUE) %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1$y,
name='Fruits - serie 1',
dataLabels=list(enabled=TRUE)) %>%
hc_add_series(df1$z,
type='column',
name='Fruits - serie 2',
dataLabels=list(enabled=TRUE)) %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)¡Nada mal! aunque es posible que no combinando el tipo de representación en las series, la visualización sea más clara, en lo que se denomina gráfico spider que es muy utilizado para las baterías o tablas de ítems en nuestras encuestas. Y ya puestos, añadimos un toque de color a nuestro gráfico. Analiza tú mismo los modificadores que cambian.
highchart() %>%
hc_chart(type = 'line',
polar=TRUE,
backgroundColor='#E2E2E2') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1$y,
name='Fruits - serie 1',
dataLabels=list(enabled=TRUE),
color='#eb6909') %>%
hc_add_series(df1$z, name='Fruits - serie 2',
dataLabels=list(enabled=TRUE),
color='teal') %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)2.8.7 Gráficos de columnas o barras con apilamiento
Volvamos la vista un poco atrás, y ahora que tenemos dos series, vamos a jugar un poco más el gráfico o más específicamente con las columnas (o barras). Vamos a realizar los apilamientos (no se pueden hacer lógicamente con los gráficos de tarta).
Recuperamos nuestro gráfico de columnas, pero lo hacemos ahora con las dos series, pero ahora, para que los dos valores (y,z) sean positivos, vamos a trabajar con el campo denominado yy el campo denominado value.
df1 <- select(df, name, y, z, value, color) # seleccionamos las columnas name, y y value
highchart() %>%
hc_chart(type = 'column') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1$y,
name='Año 1900',
dataLabels=list(enabled=TRUE),
color='#EB6909') %>%
hc_add_series(df1$value,
name='Año 2000',
dataLabels=list(enabled=TRUE),
color='#C2C2C2') %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)Nótese que hemos añadido una novedad y es la asignación a la serie del color que nos gusta para ella, mediente el modificador color en la opción hc_add_series(). Procedamos con el apilamiento.
highchart() %>%
hc_chart(type = 'column') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1$y,
name='Año 1900',
dataLabels=list(enabled=TRUE),
color='#EB6909',
stacking='normal') %>%
hc_add_series(df1$value,
name='Año 2000',
dataLabels=list(enabled=TRUE),
color='#C2C2C2',
stacking='normal') %>%
hc_credits(enabled=TRUE,
text='InvestigaOnline.com',
href ='https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)Nótese que en ambas series, se ha introducido el modificador stacking='normal'que ocasiona ese ajuste en las series. Podemos combinar series con apilamiento y series sin apilamiento (agrupaciones de categorías para verlas conjuntamente).
highchart() %>%
hc_chart(type = 'column') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(
df1$y,
name = 'Año 1900',
dataLabels = list(enabled = TRUE),
color = '#EB6909',
stacking = 'normal'
) %>%
hc_add_series(
df1$value,
name = 'Año 2000',
dataLabels = list(enabled = TRUE),
color = '#C2C2C2',
stacking = 'normal'
) %>%
hc_add_series(
df1$z,
name = 'Año 2020',
dataLabels = list(enabled = TRUE),
color = '#020202'
) %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled = TRUE)Y por último, el apilamiento puede ser normal o puede ser percent donde la representación (que no el valor mostrado) se calcula en base 100. Nótese que todas las columnas son igual de altas y nótese que nuevamente z se mantiene sin apilamiento.
highchart() %>%
hc_chart(type = 'column') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(
df1$y,
name = 'Año 1900',
dataLabels = list(enabled = TRUE),
color = '#EB6909',
stacking = 'percent'
) %>%
hc_add_series(
df1$value,
name = 'Año 2000',
dataLabels = list(enabled = TRUE),
color = '#C2C2C2',
stacking = 'percent'
) %>%
hc_add_series(
df1$z,
name = 'Año 2020',
dataLabels = list(enabled = TRUE),
color = '#020202'
) %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled = TRUE)Por último, apilemos todas …
highchart() %>%
hc_chart(type = 'column') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(
df1$y,
name = 'Año 1900',
dataLabels = list(enabled = TRUE),
color = '#EB6909',
stacking = 'percent'
) %>%
hc_add_series(
df1$value,
name = 'Año 2000',
dataLabels = list(enabled = TRUE),
color = '#C2C2C2',
stacking = 'percent'
) %>%
hc_add_series(
df1$z,
name = 'Año 2020',
dataLabels = list(enabled = TRUE),
color = '#020202',
stacking = 'percent'
) %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled = TRUE)Y pongamos el gráfico en estilo polar.
highchart() %>%
hc_chart(type = 'column', polar = 'TRUE') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(
df1$y,
name = 'Año 1900',
dataLabels = list(enabled = TRUE),
color = '#EB6909',
stacking = 'percent'
) %>%
hc_add_series(
df1$value,
name = 'Año 2000',
dataLabels = list(enabled = TRUE),
color = '#C2C2C2',
stacking = 'percent'
) %>%
hc_add_series(
df1$z,
name = 'Año 2020',
dataLabels = list(enabled = TRUE),
color = '#020202',
stacking = 'percent'
) %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled = TRUE)2.8.8 Gráfico de área
Volvamos a nuestras dos series (y, value) para presentar ahora una nueva visualización, el gráfico de área. Esta es una variación del gráfico de línea donde se dibujan éstas pero con la superficie bajo las líneas con el color indicado, mostrándose de esta forma.
highchart() %>%
hc_chart(type = 'area') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(
df1$y,
name = 'Año 1900',
dataLabels = list(enabled = TRUE),
color = '#EB6909'
) %>%
hc_add_series(
df1$value,
name = 'Año 2000',
dataLabels = list(enabled = TRUE),
color = '#C2C2C2'
) %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled = TRUE)Nótese la superposición de una y otra. Normalmente ese gráfico se usa para representar mediciones en las que una siempre está por encima de la otra (como aquí sucede), pero siempre pensando que las áreas de intersección van a combinar el color.
Podemos también apilar los valores directos.
highchart() %>%
hc_chart(type = 'area') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(
df1$y,
name = 'Año 1900',
dataLabels = list(enabled = TRUE),
color = '#EB6909',
stacking = 'normal'
) %>%
hc_add_series(
df1$value,
name = 'Año 2000',
dataLabels = list(enabled = TRUE),
color = '#C2C2C2',
stacking = 'normal'
) %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled = TRUE)O mostrar las áreas con base 100.
highchart() %>%
hc_chart(type = 'area') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(
df1$y,
name = 'Año 1900',
dataLabels = list(enabled = TRUE),
color = '#EB6909',
stacking = 'percent'
) %>%
hc_add_series(
df1$value,
name = 'Año 2000',
dataLabels = list(enabled = TRUE),
color = '#C2C2C2',
stacking = 'percent'
) %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled = TRUE)2.8.9 Gráfico de puntos o scatterplot
Variación de los anteriores vamos a presentar sus dos versiones. La versión llamemos natural sería representar los puntos (igual que en el gráfico de línea) pero sin dibujar el trazo que los une.
highchart() %>%
hc_chart(type = 'scatter') %>%
hc_xAxis(categories = df1$name) %>%
hc_add_series(df1$y, name = 'Año 1900', dataLabels = list(enabled =
TRUE)) %>%
hc_add_series(df1$value,
name = 'Año 2000',
dataLabels = list(enabled = TRUE)) %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled = TRUE)Sin embargo, cuando uno piensa en un scatterplot, lo que piensa es en un diagrama de dispersión o mapa cartesiano donde se presentan los puntos con sus coordenadas en x y también en y. Un diagrama de dispersión muestra la relación entre 2 variables numéricas. Para cada punto de datos, el valor de su primera variable se representa en el eje X, el segundo en el eje Y. Como no disponemos datos para un buen scatterplot, vamos a construirnos un banco de datos (aleatorio) y trabajamos con él.
##==================== construcción del dataframe
set.seed(311265) # para que la aleatoriedad sea siempre la misma, fijamos su semilla de aleatorización
dfextra <-
data.frame(
mat = sample(1:100, 400, replace = TRUE),
# un valor de un campo X, por ejemplo puntuación en habilidad en matemáticas
bio = sample(1:100, 400, replace = TRUE),
# un valor de un campo y, por ejemplo puntuación en habilidad en biología
glob = sample(50:100, 400, replace = TRUE),
# un valor z de peso global de adecuación al puesto
grp = sample(1:3, 400, replace = TRUE) # grupo de pertenencia (tres grupos, 1, 2 y 3)
)
##================== mostramos extracto del data frame
knitr::kable(head(dfextra)) # mostramos breve extracto de la tabla creada| mat | bio | glob | grp |
|---|---|---|---|
| 72 | 80 | 76 | 3 |
| 6 | 49 | 85 | 3 |
| 76 | 47 | 55 | 2 |
| 50 | 42 | 98 | 2 |
| 65 | 77 | 69 | 2 |
| 34 | 8 | 97 | 3 |
Y vamos con el gráfico …
hchart(dfextra, 'scatter', hcaes(x=mat, y=bio, group=grp))Puedes observar que para este tipo de gráfico hemos optado por la forma acotada; esto es debido a que la forma de ofrecerle los datos es más simple, sin embargo podemos seguir añadiendo elementos al mismo del mismo modo que lo hacíamos con el uso de la función highchart(). La agrupación por colores es debida al modificador de grupo group=grpen la función hcaes(). Si no lo ponemos, simplemente el color sería único.
hchart(dfextra, 'scatter', hcaes(x = mat, y = bio)) %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled = TRUE)Una última variación al scatterplot sería convertirlo en un bubble scatterplot. Un diagrama de burbujas es un diagrama de dispersión donde se agrega una tercera dimensión: el valor de una variable numérica adicional se representa mediante el tamaño de los puntos. Necesita 3 variables numéricas como entrada: una está representada por el eje X, una por el eje Y y otra por el tamaño del punto. Más vale un imagen que mil palabras.
hchart(dfextra, 'scatter', hcaes(
x = mat,
y = bio,
z = glob,
group = grp
)) %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled = TRUE)2.8.10 Histograma o gráfico de densidad
También en este caso vamos a recurrir a la forma simple. Un histograma solo toma como entrada una variable numérica. La variable se divide en varios cortes y el número de observaciones por corte se representa mediante la altura de la barra. Es posible representar la distribución de varias variables en el mismo eje utilizando esta técnica. Sigamos utilizando nuestro nuevo dataframe dfextra.
hchart(dfextra$mat, color = 'teal', name = 'Matemáticas') %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled = TRUE)Este gráfico puede fácilmente reconvertirse a la función de densidad. Una gráfica de densidad muestra la distribución de una variable numérica. Solo toma variables numéricas como entrada y está muy cerca de un histograma. Puede usarse exactamente en las mismas condiciones.
hchart(density(dfextra$mat), color = 'teal', name = 'Matemáticas') %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled = TRUE)2.8.11 Gráficos indicadores
Estos gráfico están caracterizados en su mayor parte por presentar un único valor numérico en una imagen muy simplificada. Su mayor exponente es el denominado gauge que estamos acostumbrados a ver en multitud de páginas web de tipo dashboard. Se caracterizan por tener datos que se proporcionan de forma externa al dataframe de donde se representa la información. Veamos algunos ejemplos.
2.8.11.1 Gauge
Un gráfico de indicador (o gráfico de velocímetro) combina un gráfico de anillo y un gráfico circular en un solo gráfico. Muestra el valor deseado al que se le presupone un valor mínimo y un máximo. Es muy típico para representar por ejemplo el NPS y presentarlo con secciones tipo semáforo. En nuestro script y con afán de ir probando nuevas cosas, crearemos primero lo que se denominan las secciones del semáforo (3 o n) y luego haremos el gráfico. Representemos el campo value de nuestras frutas, comenzando por la oliva (fila 3) . Presentamos el script de forma más extendida para ir apreciando y comentando alguno de sus detalles
col_stops <-
data.frame(
q = c(0.25, 0.50, 0.75),
# se establecen las secciones de valor en término porcentual
c = c('#CD5C5C', '#F0E68C', '#3CB371'),
# se establecen los colores que tomará cada sección
stringsAsFactors = FALSE
)
stops <-
list_parse2(col_stops) # se crea una lista con este dataframe que hemos creado, pues highcharts lo necesita así.
highchart() %>%
hc_chart(type = "solidgauge") %>%
hc_pane(
startAngle = -90,
# determina el ángulo donde comienza
endAngle = 90,
# determina el ángulo donde acaba
background = list(
outerRadius = '100%',
# "vaciamos" el hueco del círculo que hemos dibujado
innerRadius = '60%',
# "vaciamos" el hueco del círculo que hemos dibujado
shape = "arc"
)
) %>%
hc_tooltip(enabled = FALSE) %>%
hc_yAxis(
stops = stops,
# le aplicamos la lista de secciones colo (semáforo)
lineWidth = 0,
minorTickWidth = 0,
tickAmount = 2,
min = 0,
max = 100,
labels = list(y = 25) # baja las etiquetas 0 y 100 de límites para que no sitúen sobre el gráfico
) %>%
hc_add_series(
data = df$high[3],
# le indicamos que capturamos el valor desde dataframe 'df', del campo 'high', y la fila '3'
dataLabels = list(
borderWidth = 0,
useHTML = TRUE,
style = list(fontSize = "60px")
)
) %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled = TRUE)Prueba si lo deseas a ir cambiando el valor de df$high[3] a cualquier valor entre 0 y 10 y observarás el cambio de color.
col_stops <-
data.frame(
q = c(0.25, 0.50, 0.75),
c = c('#CD5C5C', '#F0E68C', '#3CB371'),
stringsAsFactors = FALSE
)
stops <- list_parse2(col_stops)
highchart() %>%
hc_chart(type = "solidgauge") %>%
hc_pane(
startAngle = -90,
endAngle = 90,
background = list(
outerRadius = '100%',
innerRadius = '60%',
shape = "arc"
)
) %>%
hc_tooltip(enabled = FALSE) %>%
hc_yAxis(
stops = stops,
lineWidth = 0,
minorTickWidth = 0,
tickAmount = 2,
min = 0,
max = 100,
labels = list(y = 25)
) %>%
hc_add_series(data = 65,
dataLabels = list(
borderWidth = 0,
useHTML = TRUE,
style = list(fontSize = "60px")
)) %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)2.8.11.2 Bullet
Otra forma de representar valores unitario pero que tienen un objetivo definido y que pueden haber superado ese objetivo es el gráfico denominado bullet. vamos a imaginar que en nuestro dataframe, y es el valor alcanzado, y valuees el objetivo.
bandas <-
list(
list(
from = 0,
to = 10,
color = "#ddd"
),
list(
from = 10,
to = 20,
color = "#bbb"
),
list(
from = 20,
to = 25,
color = "#888"
)
)
hchart(
df1,
"bullet",
hcaes(x = name, y = y, target = value),
color = "teal",
targetOptions = list(color = 'black')
) %>%
hc_chart(inverted = TRUE) %>%
hc_yAxis(
min = 0,
max = 25,
gridLineWidth = 0,
plotBands = bandas
) %>%
hc_xAxis(gridLineWidth = 15, gridLineColor = "white") %>%
hc_plotOptions(series = list(
pointPadding = 0.25,
pointWidth = 15,
borderWidth = 0,
targetOptions = list(width = '200%')
)) %>%
hc_size(height = 300) %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled = TRUE)Nótese que en el gráfico la barra vertical perpendicular a cada barra horizontal, que es el target se toma de los propios datos. Es un gráfico que también se ve mucho en los dashboard, al igual que el anterior.
2.8.12 Gráfico o boxplot
No lo hemos olvidado, el gráfico más típico en estadística junto con los histogramas, el denominado boxplot o diagrama de caja o diagrama de Box-Whiskers. Un diagrama de caja ofrece un buen resumen de una o varias variables numéricas. La línea que divide el cuadro en 2 partes representa la mediana de los datos. El final del cuadro muestra los cuartiles superior e inferior. Las líneas extremas muestran el valor más alto y más bajo excluyendo los valores atípicos. Nótese que es usada una función de tranformación de los datos del campo valuepara obtener los valores adecuados para el gráfico. Del mismo modo, nótese que la función de adición de las series, se ve mínimamente modificada ya que va a recibir una lista de valores por cada campos de trabajo. Usamos hc_add_series_list().
dfboxplot1 <-
data_to_boxplot(df,
value,
add_outliers = TRUE,
name = 'value',
color = 'teal')
highchart() %>%
hc_chart(type = 'boxplot') %>%
hc_add_series_list(dfboxplot1) %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled=TRUE)Añadir más series sólo implica repetir el proceso, lo que permite la compración.
dfboxplot1 <-
data_to_boxplot(df,
value,
add_outliers = TRUE,
name = 'value',
color = 'teal')
dfboxplot2 <-
data_to_boxplot(df,
high,
add_outliers = TRUE,
name = 'high',
color = 'red')
dfboxplot3 <-
data_to_boxplot(
df,
low,
add_outliers = TRUE,
name = 'low',
color = 'orange'
)
highchart() %>%
hc_chart(type = 'boxplot') %>%
hc_add_series_list(dfboxplot1) %>%
hc_add_series_list(dfboxplot2) %>%
hc_add_series_list(dfboxplot3) %>%
hc_credits(enabled = TRUE,
text = 'InvestigaOnline.com',
href = 'https://www.investigaonline.com') %>%
hc_exporting(enabled = TRUE)2.8.13 Gráfico de barras de error
A menudo tenemos necesidad de incluir un gráfico denominado de barras de error. Este gráfico toma los valores de low-high (que podrían ser lo límites de confianza de un intervalo) y los representa en forma gráfica, quedando de esta forma.
highchart() %>%
hc_chart(type = 'errorbar', polar = FALSE, inverted = FALSE) %>%
hc_xAxis(categories = df$name) %>%
hc_yAxis(visible = TRUE) %>%
hc_tooltip(outside = TRUE, enabled=TRUE) %>%
hc_add_series(df,name = "Límites de confianza",showInLegend = FALSE, dataLabels = list(enabled=TRUE))Si además de los límites de la medición, quisiéramos añadir el punto de valor, el resultado sería éste.
highchart() %>%
hc_chart(type = 'errorbar', polar = FALSE, inverted = FALSE) %>%
hc_xAxis(categories = df$name) %>%
hc_yAxis(visible = TRUE) %>%
hc_tooltip(outside = TRUE, enabled=TRUE) %>%
hc_add_series(df,name = "Límites de confianza",showInLegend = FALSE, dataLabels = list(enabled=TRUE)) %>%
hc_add_series(df,type = 'scatter', name = "Valor",showInLegend = FALSE, dataLabels = list(enabled=TRUE, x=15, y=5))Probando nuevas cosas, hemos movido la etiqueta del valor hacia la derecha (x=15) y hacia abajo (y=5). Eso hace que no se solape con el punto señalado en el gráfico.
2.8.14 Gráficos de transiciones
En nuestro trabajo en mucho casos debemos a veces plantear gráficos en los que se trata de graficar relaciones de objetos con fuente y destino. Aunque nuestro banco de datos es muy simple, hemos creado campos con el nombrede weight, from y to para que nos permitan hacer este tipo de gráficos que tienen dos versiones diferentes: el diagrama de Sankey y el diagrama de rueda de dependencia. Veamos ambos.
2.8.14.1 Diagrama de Sankey
El diagrama de Sankey es un tipo específico de diagrama de flujo, en el que la anchura de las linea de relación entre dos puntos (from y to) se muestra proporcional a la cantidad de flujo transferido (weight, que podría ser frecuencia de emparejamiento).
highchart() %>%
hc_chart(type = 'sankey', polar = FALSE, inverted = FALSE) %>%
hc_xAxis(categories = df$name) %>%
hc_yAxis(visible = TRUE) %>%
hc_tooltip(outside = TRUE, enabled=TRUE) %>%
hc_add_series(df,name = "Nombre de la serie",showInLegend = FALSE, dataLabels = list(enabled=TRUE), colorByPoint=TRUE)De esta forma se muestra que las relaciones más fuertes se producen entre aceituna y pera o entre guava y pera.
2.8.14.2 Diagrama de rueda
Otra forma de ver el mismo gráfico, pero en forma circular. Las mismas necesidades de campos weight, from y to.
highchart() %>%
hc_chart(type = 'dependencywheel',
polar = FALSE,
inverted = FALSE) %>%
hc_xAxis(categories = df$name) %>%
hc_yAxis(visible = TRUE) %>%
hc_tooltip(outside = TRUE, enabled = TRUE) %>%
hc_add_series(
df,
name = "Nombre de la serie",
showInLegend = FALSE,
dataLabels = list(enabled = TRUE),
colorByPoint = TRUE
)2.8.14.3 Diagrama streamgraph
Un streamgraph es un tipo de gráfico de áreas apiladas. Muestra la evolución de un valor numérico (eje Y) después de otro valor numérico (eje X). Esta evolución está representada por varios grupos, todos con un color distinto. Al contrario que en un área apilada, no hay esquinas: los bordes están redondeados, lo que da esta agradable impresión de flujo. Además, las áreas generalmente se desplazan alrededor de un eje central, lo que da como resultado una forma fluida y orgánica.
Usaremos los valores y, z y value para crear tres series.
highchart() %>%
hc_chart(type = 'streamgraph',
polar = FALSE,
inverted = FALSE) %>%
hc_xAxis(categories = df$name) %>%
hc_yAxis(visible = TRUE) %>%
hc_tooltip(outside = TRUE, enabled = TRUE) %>%
hc_add_series(
df$y,
name = "y",
showInLegend = FALSE,
dataLabels = list(enabled = FALSE),
color = 'silver'
) %>%
hc_add_series(
df$z,
name = "z",
showInLegend = FALSE,
dataLabels = list(enabled = FALSE),
color = 'teal'
) %>%
hc_add_series(
df$value ,
name = "value",
showInLegend = FALSE,
dataLabels = list(enabled = FALSE),
color = 'orange'
)2.8.15 Conclusión
Hasta aquí llegamos. Hemos presentado de forma muy breve y simplificada como podemos aprovechar toda la potencia de highcharts en nuestros script. Lo importante es practicar y practicar. No dejes de leer el post de Danton Noriega acerca de como usar la API para saber construir los gráficos highchart en R mediante highcharteR Del mismo modo, no dejes de acudir al sitio web de Joshua Kunst, creador y mantenedor del paquete junto con otros colaboradores que permiten llevar adelante este excelente proyecto.